最近在项目中遇到了一个因为 TCP RST 而导致集成测试用例运行失败的问题,简单用文字在此跟大家分享一下。
背景信息
我们的后端项目是包含了多个组件的微服务系统,数据库使用的是 Postgres。通常在进行集成测试时,我们会使用 Kind 将整个后端组件以及依赖的 Postgres、Redis 等中间件运行起来,然后通过 port-forward 方式暴露到宿主机上,这样运行在宿主机上的 Ginkgo (Golang 集成测试框架)就可以访问到 Kind 中运行的后端服务了。这一套测试框架在依赖 Kubernetes 的项目中比较常见,使用起来也很便捷。
而这次的问题出现在,我们将集成测试中的 k8s.io/client-go 依赖从 v0.22.4 升级到 v0.24.0 版本后,测试用例中通过 port-forward 方式访问 Postgres 时,总是会出现失败的情况。
排查过程一:分析并找到初步原因
锁定 Port-Forward 断开的原因
刚发现问题的时候,我们并不知道是因为升级 k8s.io/client-go 导致的问题,因为出现问题的 Pull Request 中还有很多其他的变更。所以我们首先还是通过查看错误日志,得到了如下信息:
1E0610 07:20:46.199054 25339 portforward.go:406] an error occurred forwarding 35169 -> 5432: error forwarding port 5432 to pod d9229db6040a461f038cf546c5efc39c407f48d015b603855882f2a94a9c028a, uid : failed to execute portforward in network namespace "/var/run/netns/cni-d75c685d-0da5-a6c9-9891-ffba16e23531": read tcp4 127.0.0.1:51062->127.0.0.1:5432: read: connection reset by peer
2E0610 07:20:46.199530 25339 portforward.go:234] lost connection to pod
对比了旧代码的运行日志,发现其中也会打印第一行日志,但是没有第二行 lost connection to pod。 根据这个关键信息,我们继续翻看了 kubernetes portforward 包下的代码:
1// wait for interrupt or conn closure
2select {
3case <-pf.stopChan:
4case <-pf.streamConn.CloseChan():
5 runtime.HandleError(errors.New("lost connection to pod"))
6}上述代码显示,只有在 pf.streamConn 被关闭时才会打印 lost connection to pod,搜索 pf.streamConn.Close() 相关代码,最终锁定了以下信息:
1// always expect something on errorChan (it may be nil)
2err = <-errorChan
3if err != nil {
4 runtime.HandleError(err)
5 pf.streamConn.Close()
6}Git Blame 这段代码,发现是由于该 PR 实现的一个优化导致了问题。
该 PR 涉及的优化细节为:在 port-forward 的 Pod 侧连接(kubelet -> postgres)出现 error 时,让 port-forward 自身被关闭。这是为了解决 kubectl 对某个 pod 执行了 port-forward 后,该 pod 死掉的情况下(比如被删除了),kubectl 可以自动退出,而不至于一直继续运行。
经过上面的分析,我们锁定了是因为 port-forward 在 pod 侧的连接出现了 error,结合日志 read tcp4 127.0.0.1:51062->127.0.0.1:5432: read: connection reset by peer 分析,也就是说在 kubelet 发起的 51062 端口到 Postgres 5432 的 TCP 连接中,出现了 Postgres 发出的 TCP RST 包。
为什么 Postgres 会发出 TCP RST 包?
下一步就是要分析为什么 Postgres 会发出 RST 包。在这里,我们可以使用最新版本(v1.24.2)的 kubectl 来尝试复现集成测试中遇到的问题。
首先开启 port-forward。
1❯ ./kubectl port-forward pod/postgres-0 5432:5432
2Forwarding from 127.0.0.1:5432 -> 5432
3Forwarding from [::1]:5432 -> 5432然后使用 psql 通过 port-forward 查询 Postgres。需注意,由于我们的 Postgres 开启了客户端证书校验,所以需要为 psql 指定客户端证书和私钥。
1PGPASSWORD="123456" PGSSLCERT=./tls.crt PGSSLKEY=./tls.key psql -t -h 127.0.0.1 -U postgres -d postgres -c "select 1;"port-forward 日志打印如下:
1Handling connection for 5432
2E0711 00:01:28.334216 3041058 portforward.go:406] an error occurred forwarding 5432 -> 5432: error forwarding port 5432 to pod ebb9210ccf74b8047be4c6e8a23237c460a33235b2f6c65430ecd680f70e71cf, uid : failed to execute portforward in network namespace "/var/run/netns/cni-d8bfc8cf-2434-540c-9e60-f71f81de7ac0": read tcp4 127.0.0.1:36252->127.0.0.1:5432: read: connection reset by peer
3E0711 00:01:28.334458 3041058 portforward.go:234] lost connection to pod在复现的同时,我们使用 tcpdump 抓取 postgres 5432 端口的包以及使用 strace 记录 Postgres 进程发起的系统调用。根据复现异常时的日志中 36252 端口作为关键字,在 tcpdump 和 strace 输出中过滤得到如下信息。
tcpdump 输出信息:
100:01:28.330748 IP 127.0.0.1.36252 > 127.0.0.1.5432: Flags [P.], seq 1866:1903, ack 2595, win 512, options [nop,nop,TS val 2518407611 ecr 2518407610], length 37
200:01:28.330750 IP 127.0.0.1.5432 > 127.0.0.1.36252: Flags [.], ack 1903, win 512, options [nop,nop,TS val 2518407611 ecr 2518407611], length 0
300:01:28.331087 IP 127.0.0.1.5432 > 127.0.0.1.36252: Flags [P.], seq 2595:2683, ack 1903, win 512, options [nop,nop,TS val 2518407611 ecr 2518407611], length 88
400:01:28.331789 IP 127.0.0.1.36252 > 127.0.0.1.5432: Flags [P.], seq 1903:1930, ack 2683, win 512, options [nop,nop,TS val 2518407612 ecr 2518407611], length 27
500:01:28.331793 IP 127.0.0.1.5432 > 127.0.0.1.36252: Flags [.], ack 1930, win 512, options [nop,nop,TS val 2518407612 ecr 2518407612], length 0
600:01:28.331803 IP 127.0.0.1.36252 > 127.0.0.1.5432: Flags [P.], seq 1930:1954, ack 2683, win 512, options [nop,nop,TS val 2518407612 ecr 2518407612], length 24
700:01:28.331805 IP 127.0.0.1.5432 > 127.0.0.1.36252: Flags [.], ack 1954, win 512, options [nop,nop,TS val 2518407612 ecr 2518407612], length 0
800:01:28.332296 IP 127.0.0.1.5432 > 127.0.0.1.36252: Flags [P.], seq 2683:2707, ack 1954, win 512, options [nop,nop,TS val 2518407613 ecr 2518407612], length 24
900:01:28.333718 IP 127.0.0.1.5432 > 127.0.0.1.36252: Flags [R.], seq 2707, ack 1954, win 512, options [nop,nop,TS val 2518407614 ecr 2518407612], length 0
strace 输出信息:
13431299 accept(3, {sa_family=AF_INET, sin_port=htons(36252), sin_addr=inet_addr("127.0.0.1")}, [128->16]) = 9
23431299 clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7fbba752ec50) = 1323730
33431299 close(9)
4...
51323730 fcntl(9, F_GETFL) = 0x2 (flags O_RDWR)
61323730 fcntl(9, F_SETFL, O_RDWR|O_NONBLOCK) = 0
7...
81323730 recvfrom(9, "\27\3\3\0 ", 5, 0, NULL, NULL) = 5
91323730 recvfrom(9, "...", 32, 0, NULL, NULL) = 32
101323730 sendto(9, "...", 88, 0, NULL, 0) = 88
111323730 recvfrom(9, "\27\3\3\0\26", 5, 0, NULL, NULL) = 5
121323730 recvfrom(9, "...", 22, 0, NULL, NULL) = 22
131323730 sendto(9, "...", 24, 0, NULL, 0) = 24
141323730 exit_group(1) = ?
151323730 +++ exited with 1 +++
通过分析上述 strace 结果,我们会发现 Postgres 采用了很传统的进程模型,即每个连接启动一个子进程去处理。在上述日志中,3431299 进程在接收到新的连接(36252 -> 5432)时克隆出了 1323730 子进程去处理。
通过对比 tcpdump 和 strace 的输出,会发现来自 36252 最后一个 24 字节大小的包没有被 1323730 进程读取,而这正是导致内核返回 RST 包的原因。
在正常情况下,如果进程退出或者对 Socket 主动执行 Close 系统调用,内核会发出 FIN 包,进入四次挥手流程。但是在当前的场景下,内核发现在断开连接时还存在一些数据没有被应用层读取,应用就已经退出的情况,导致内核不得不使用 RST 包,以此来告诉客户端“你发送的一些数据没有被服务端读取,这是一次异常的 TCP 断连”。
那么这个没有被读取的 24 字节包到底是什么呢?
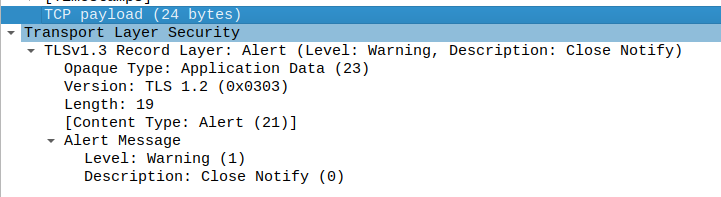
前文中提到我们使用的 Postgres 是开启了 mTLS 模式的,所以整个连接都是 TLS。在断开连接时,就会发出 TLS 协议中的 “Close Notify” 包。下图展示了一个 TLS 连接的生命周期:
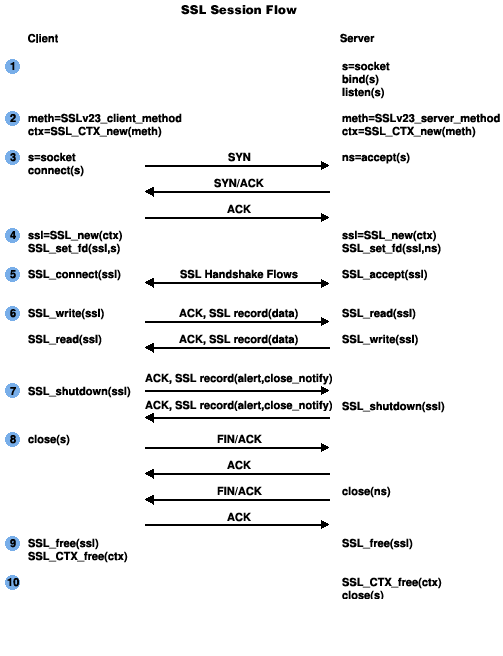
结合到 Postgres TLS 连接场景下,Client (psql)和 Server(Postgres)都会给对方发送 close_notify,但是也都没有等对方的响应就直接关闭了 TCP 连接,所以两边都各自产生了一个 RST,下面是 psql 侧抓包的结果:
100:36:56.015219 IP 127.0.0.1.39248 > 127.0.0.1.5432: Flags [P.], seq 1903:1930, ack 2683, win 512, options [nop,nop,TS val 2520535295 ecr 2520535295], length 27
200:36:56.015229 IP 127.0.0.1.39248 > 127.0.0.1.5432: Flags [P.], seq 1930:1954, ack 2683, win 512, options [nop,nop,TS val 2520535295 ecr 2520535295], length 24
300:36:56.015426 IP 127.0.0.1.39248 > 127.0.0.1.5432: Flags [F.], seq 1954, ack 2683, win 512, options [nop,nop,TS val 2520535296 ecr 2520535295], length 0
400:36:56.015427 IP 127.0.0.1.5432 > 127.0.0.1.39248: Flags [.], ack 1954, win 512, options [nop,nop,TS val 2520535296 ecr 2520535295], length 0
500:36:56.016076 IP 127.0.0.1.5432 > 127.0.0.1.39248: Flags [P.], seq 2683:2707, ack 1955, win 512, options [nop,nop,TS val 2520535296 ecr 2520535296], length 24
600:36:56.016104 IP 127.0.0.1.39248 > 127.0.0.1.5432: Flags [R], seq 2542047690, win 0, length 0
前三个包分别是 Postgres 协议中的 Termination、SSL 层的 close_notify 和 TCP 层 FIN。psql 一次性就把自己断开连接要发送的指令都发完了,结果服务端又返回了一个 SSL close_notify。
此时因为这个 Socket 的 fd 已经被 psql 关掉了,内核也就知道这个数据包 psql 是没法读取的了,也就不得不出现一个 RST 了。
总结
经过上面的分析可以看出,在 Postgres 开启 TLS 模式的前提下,客户端跟 Postgres 的连接断开流程中一定会产生 RST,所以我们暂时调高了集成测试中 Postgres 客户端的 IdleTimeout,让连接在测试运行过程中不要断开,一直保持连接状态,暂时绕过了这个问题。
排查过程二:解决新问题
Postgres 的问题暂时解决后,很快又发现了新的问题。一些关于 APISIX HTTPS 的测试用例会出现偶发挂掉。
通过查看日志,我们发现对于 APISIX HTTPS 端口的 port-forward 挂掉状况,总是发生在请求了 60s 后,跟默认的 keepalive_timeout 配置符合。通过抓包,我们确定了闲置的连接确实在 60s 后被 APISIX 主动断开了。以下是断开连接时的抓包截图:
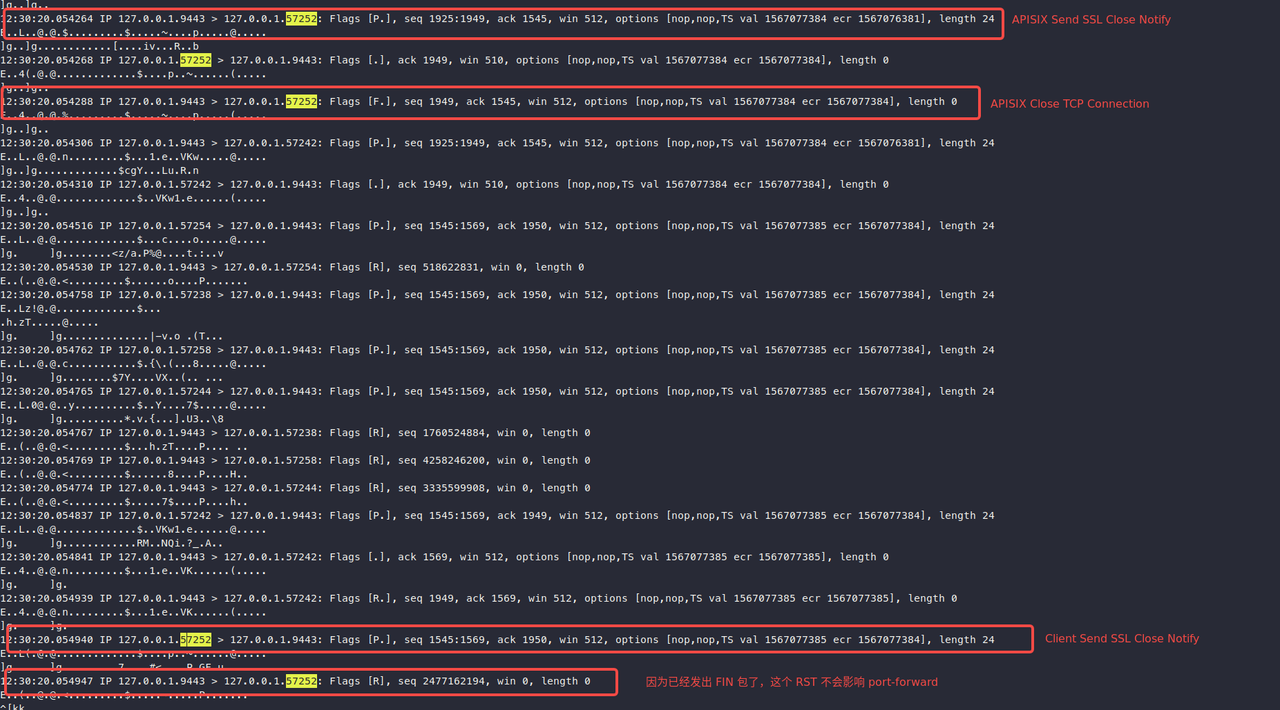
通过图中信息可以看到,这次断开连接的流程确实存在 RST 包,原因与 Postgres 场景下类似。即 APISIX 断开连接时会发出 ssl close notify 包,客户端收到后会回复 ssl close notify,但是 APISIX 并没有读取客户端发送的这条返回信息。
但问题是发生在上述断开连接的流程中, port-forward 并没有因为这个 RST 包被关闭掉。原因是 APISIX 已经发出了 FIN 包,kubelet 在收到 FIN 包后(read EOF),也开始关闭自己的 fd,也就不会再读取这个 fd 了,所以这个 RST 对它没有影响。
但同时我们注意到,APISIX 发送 SSL Close Notify(SSL_shutdown) 和发出 FIN (close)其实是两次顺序执行的调用,那么有没有可能是在这两步之间,客户端的 SSL Close Notify 横插一脚,也就是说 FIN 包还没有发出去,客户端的 SSL Close Notify 就已经到了(因为整个网络都是在同一台宿主机上,延迟很低),此时就可能会导致 RST。
思来想去我们认为只有上面这种可能,便开始尝试复现这种情况。首先将 APISIX 的 keepalive timeout 配置调小(3s),这样可以快速模拟 timeout 后断开连接,然后执行一个客户端每次发起 10 个连接,等待 APISIX 关闭连接。循环执行,直到 port-forward 挂掉,在一段时间后,果然复现了问题,以下是异常请况下的抓包截图:
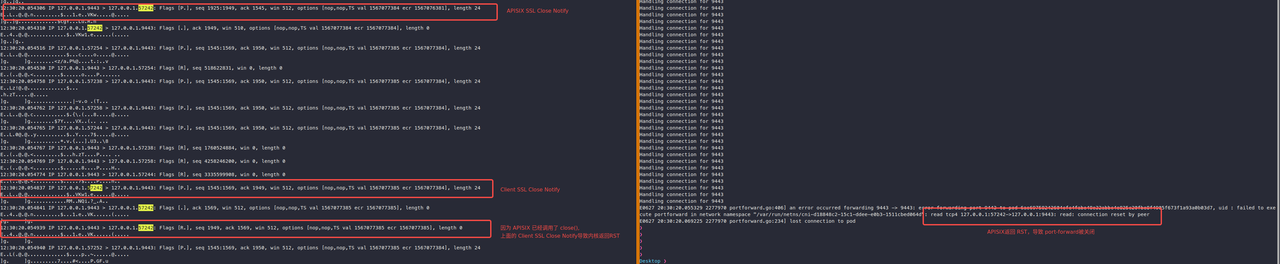
抓包结果显示,上述猜想是正确的。
总结
在网络延迟很低的情况下,由 APISIX 主动断开的 SSL 连接可能会触发 RST,所以我们在集成测试中将客户端的 keepalive timeout 配置为小于 APISIX 的 60s,这样就可以让客户端先断开连接,也就不会触发 APISIX 可能发出 RST 的情况。
后记
可以看到 APISIX 和 Postgres 在断开 SSL 连接时,都不会理会客户端的 Close Notify,TLS 的标准中可能压根也没有规定一定要读取对端的 Close Notify 包,而这正是导致出现 TCP RST 的根本原因。
以上就是本次分析 RST 问题的全部过程,其中关于 Postgres、Kubelet 、APISIX、内核等行为的分析大多都是基于使用 tcpdump 和 strace 观测所得,尚没有深入到源码,所以在理解上可能有误,欢迎大家指摘。但整个分析思路和方法对类似的 RST 问题是通用的,可以进行相关参考。