随着 API 在现代开发中的广泛应用,对高效可靠的 API 网关的需求也在不断增加。API 网关在整个系统中充当着传入 API 请求的单一入口,其使命是高效地管理这些请求,并将这些请求分发到各个微服务中。尽管 API 网关带来了诸多好处,但在处理高流量场景时也可能面临一些挑战。
下面的流程图详细展示了 APISIX 采用的高效缓存机制,以降低延迟并提升性能。通过在多个层次上缓存 API 响应,APISIX 能够有效减轻上游服务器的负载,为客户提供更为灵敏的使用体验。
1Client <-- HTTP Request --> APISIX Worker
2 (Check LRU Cache in process level)
3 (No cache hit)
4 (Check Shared DICT Cache in data plane level)
5 (Lock not acquired)
6 (Acquire lock, check cache)
7 (Cache hit)
8 (Return cached response, release locks)
9 (Cache miss)
10 (Query Redis)
11 (Acquire Mutex)
12 (Query Redis)
13 (Cache miss)
14 (Retrieve response from upstream)
15 (Cache response in shared DICT cache)
16 (Return response to client)
17 (Cache hit)
18 (Copy response to shared DICT cache)
19 (Return cached response to client)
20 (Release Redis Mutex)
21 (Release lock)
22 (Cache hit)
23 (Return cached response)
LRU
APISIX 中 Worker 层的 LRU(Least Recently Used,最近最少使用)缓存是在每个工作进程中负责缓存频繁访问的数据的关键组件。它采用 LRU 淘汰算法,通过高效存储和检索数据,实现了对最近最少使用的数据的优先处理。通过将频繁访问的数据缓存到内存中,APISIX 显著降低了查询外部数据源时的延迟和相关开销,从而提高了系统的响应速度。
通过这一智能缓存机制,APISIX 在处理大量请求时能够更为高效地利用系统资源,提升了系统的整体性能和稳定性。APISIX 通过其先进的 LRU 缓存系统,为开发工程师提供了一个可靠、高效的 API 网关解决方案,助力业务更加顺畅地与外部服务进行通信。
Shared Dict
数据面的共享内存字典(shared dict)缓存是一种分布式缓存,覆盖所有工作进程,其功能是充当常用数据的中心化缓存,包括 API 响应数据或响应头。多个工作进程能够同时访问和更新这个缓存,以确保数据一致性,并避免不必要的数据重复。这一共享内存字典缓存在性能方面表现卓越,采用了内存锁定和高效的数据结构等先进技术。这使得它能够实现最小化争用并最大化吞吐量的目标。通过内存锁定,它有效地控制并发访问,确保在多个工作进程同时进行读写操作时的一致性。高效的数据结构设计使得共享内存字典缓存能够更快地执行数据检索和更新操作,提高了整体性能。
共享内存字典缓存的引入为 APISIX 的数据平面注入了更强大的性能和可伸缩性,为研发工程师提供了一个可靠的工具,助力其在处理大规模数据和请求时取得卓越的表现。
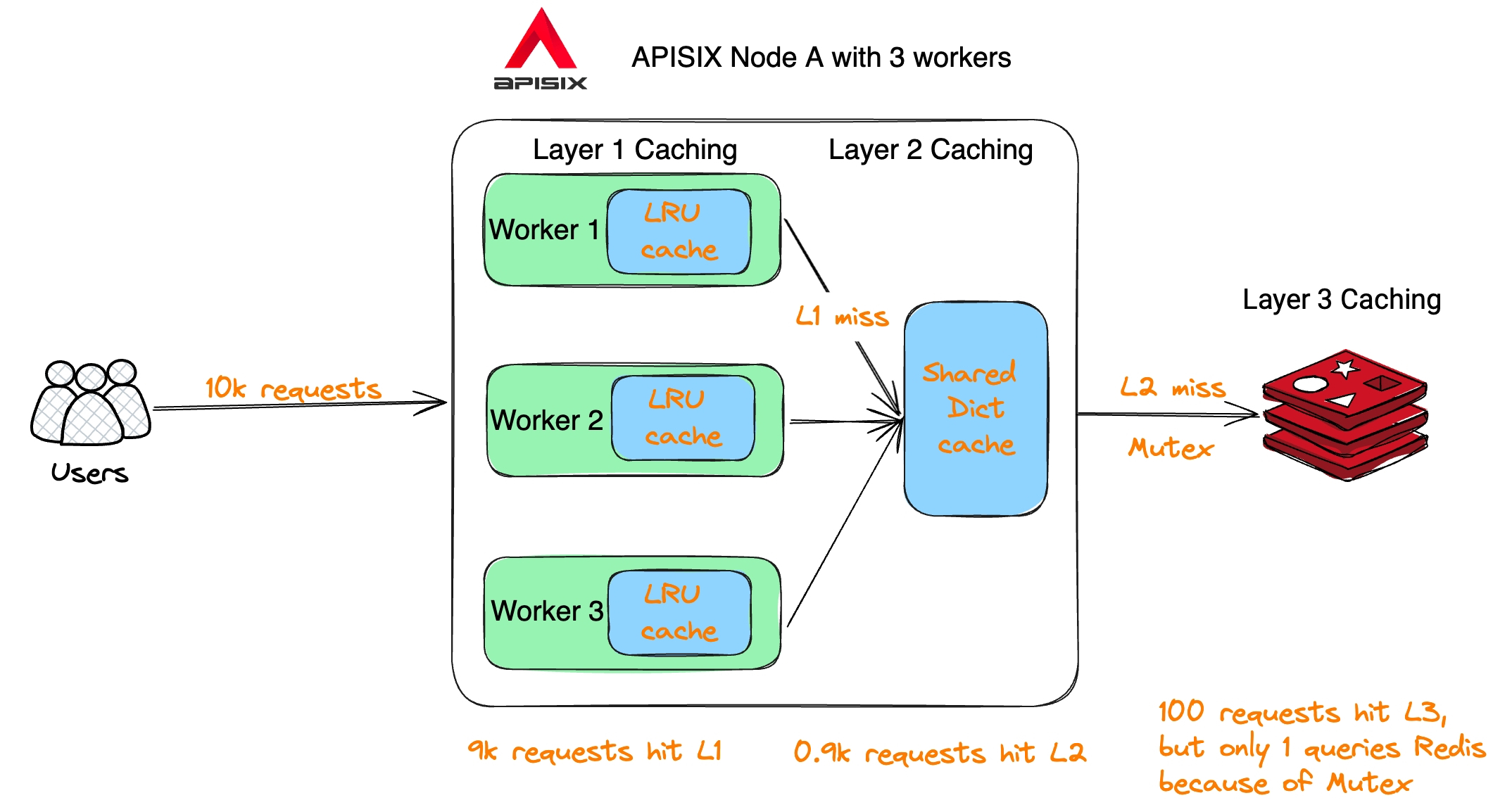
APISIX 多层缓存机制
下图展示了 APISIX 的多层缓存机制,类似于漏斗原理。具体来说,L1 缓存采用了 worker 内部的 LRU 内存缓存,L2 缓存为多个 worker 之间共享的 shared dict,L3 为 API 网关外部的 Redis。
举例说明:当有 10,000 个用户请求通过 APISIX 查询数据,假设 L1 缓存的命中率为 90%,那么 9000 个请求会直接返回;剩下 1000 个请求则去 L2 缓存查询,假设 L2 缓存的命中率也是 90%,那么剩下 100 个请求将会去查询 Redis;这 100 个请求在去查询 Redis 之前,会去查询互斥锁,保证同时只有一个请求去查询 Redis,防止出现缓存风暴。
总结
通过充分发挥多层次缓存的作用,APISIX 能够高效处理大部分客户请求,无需频繁查询诸如 Redis 或 Postgres 之类的外部数据存储组件。这不仅显著降低了总体延迟,还提升了 API 网关的吞吐量,为企业提供了高效而强大的解决方案,简化了与外部服务的通信。这种优化设计使得系统更为稳健,能够更灵活应对高并发情境,为研发工程师创造了更可靠、高性能的开发环境。