How to Avoid Catastrophic Backtracking in Regex?
API7.ai
December 17, 2020
Catastrophic Backtracking of regular expressions refers to the fact that the regular expression backtracks too much when it matches, causing 100% CPU and blocking normal services.
Background
I have read an article detailing the discovery and resolution process of a regular backtrace leading to 100% CPU. The original article is rather long, and I've encountered similar problems twice before in OpenResty development.
Here's a brief summary so you don't have to spend time on the background.
- Regularization engines for most development languages are implemented using backtracking-based NFA (rather than based on Thompson's NFA).
- catastrophic backtracking with 100% CPU if there are too many backtrackings.
- need to analyze the dump with gdb, or systemtap to locate the online environment.
- Such problems are difficult to detect before the code goes live and require a case-by-case review of the regular expressions.
From a development point of view, fixing the problematic regular expressions is the end of the story. At most, add a safety mechanism to limit the number of backtracking, such as this in OpenResty.
lua_regex_match_limit 100000;
This way, even if there is a catastrophic backtracking, it will be limited and will not run full CPU.
Well, does it look perfect already? Let's go beyond the development level and look at this in a different dimension.
Attackers
Just use a machine, send a request, you can hit across the other side of the server, this is simply a hacker's dream of nuclear weapons. Compared to this, what DDoS is weak, the movement is large and costly.
This attack also has its own name: the ReDoS (RegEx Denial of Service)。
Since regular expressions are so widely used and exist in almost every part of the back-end service, there is an opportunity to take advantage of it by finding one of the vulnerabilities.
Imagine a scenario where a hacker discovers a ReDoS vulnerability in the WAF and sends a request to bring down the WAF; you are unable to locate the problem in a short period of time, not even realizing it is an attack; you choose to restart or temporarily shut down the WAF to keep your business on track; while the WAF is out of action, the hacker uses SQL injection to drag away your database. You, on the other hand, may still be completely in the dark.
Due to the widespread use of open source software and cloud services, it is not enough to just make sure that the regular expressions you write are free of vulnerabilities. That's another topic, we'll start here with only discussing regulars that are within our own control.
How to discover such regular expressions?
The first step in solving problems is to find them, and to try to find all of them, also known as the ability to find them safely.
Expecting a manual code review to find problematic rules is not reliable. Most developers are not security conscious, and even if they were to look for them, it is unlikely that they would be able to find the problem in a complex regular expression.
This is where automation tools come in handy.
We have the following two automated methods to solve this.
- Static testing
Such tools can scan the code for regular expressions and, according to a certain algorithm, find out the regulars with catastrophic backtracking from them.
For example, RXXR2, which is implemented based on an algorithm in a paper that converts regular to ε-NFA and then search for it, but does not support the extended syntax of regular expressions, so there will be missed reports.
- Dynamic fuzzing
The fuzz test is a general software testing method that detects software crashes, memory leaks, and other problems by entering large amounts of random data over long periods of time.
Similarly, we can use this approach in regular tests. We can generate test data based on existing regular expressions, or we can generate them completely at random.
SlowFuzz is one of the open source tools, also based on a paper implementation of the algorithm, the paper will be listed at the end of this paper, it is a general-purpose tool, and does not do processing for the structure of the regular, so there will be missed reports.
SDLFuzzer is a specialized ReDoS detection tool developed by Microsoft a few years ago, but is no longer maintained.
There are not many tools to choose from in this area, and there is not much attention. However, I was excited to find a paper on ReDoS by several teachers and PhD's from Nanjing University during my search for information, and open source the tool ReScue together with the paper: https://2bdenny.github.io/ReScue/. This tool has identified ReDoS vulnerabilities in several open source projects.
Here are the results of the comparison tests in paper.
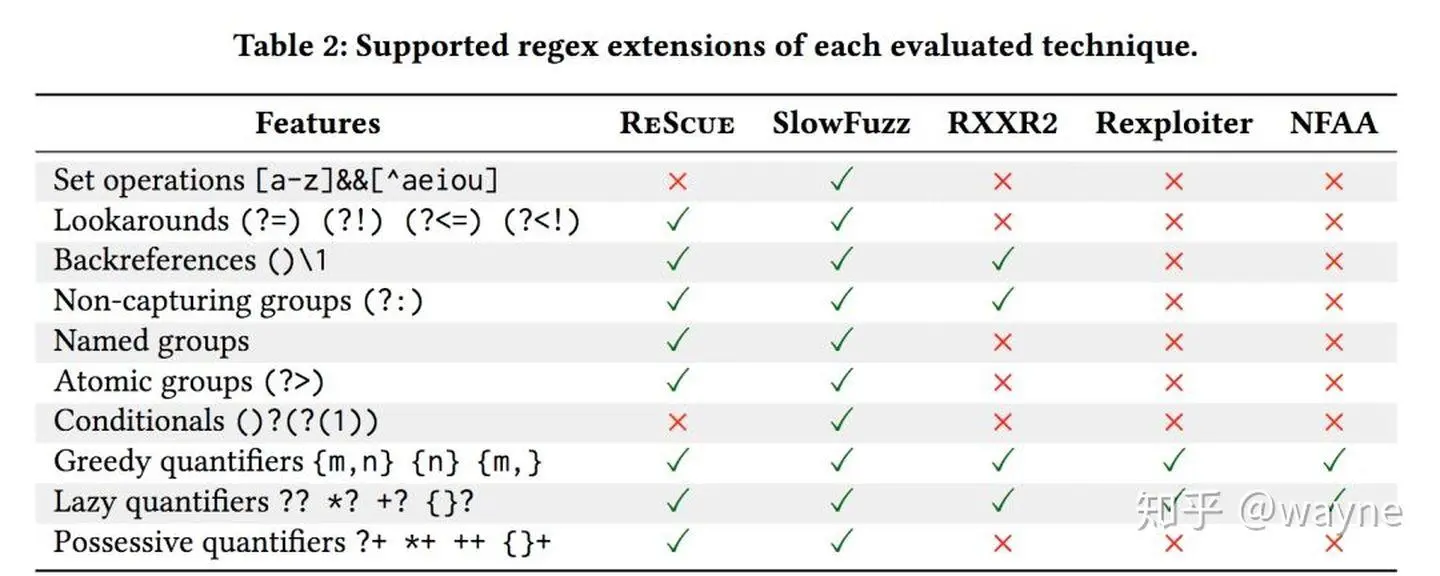
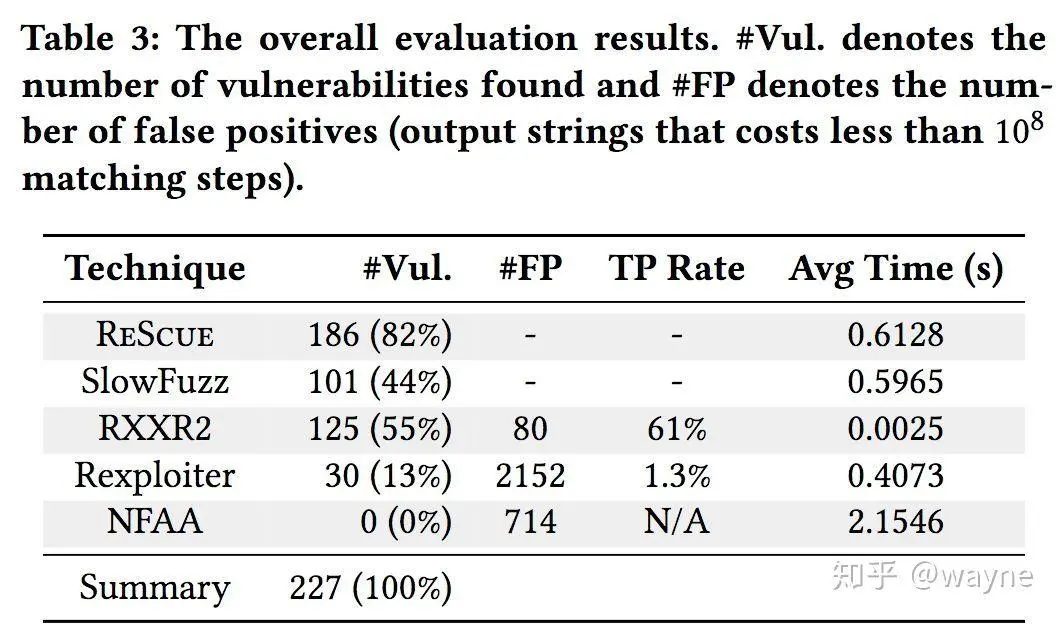
Can it be done once and for all?
Even if we use such tools, there will inevitably be false alarms and missed alarms, so is there a once-and-for-all way to solve ReDoS?
Then we have to go back to the root of the problem to find the answer: the regular engine uses backtracking to match.
Wouldn't it be OK if we abandoned this approach? Yes, there are already quite a few other implementations of regular engines that can be solved once and for all. They all give up backtracking and use the NFA/DFA automaton approach to implement, the advantage is that it is suitable for streaming matching and is also safer, the disadvantage is that it does not support many regular extension syntaxes, such as backreferences, well these are generally not used either.
- Google RE2
Google's RE2 is one of the more completed open source projects. It supports most of the syntax of PCRE, and there are Go, Python, Perl, Node.js and other development languages library implementation, start and replacement cost is very low.
Let's take Perl as an example and see if RE2 can avoid catastrophic backtracking problems.
Let's take a look at this comparative chart of results.
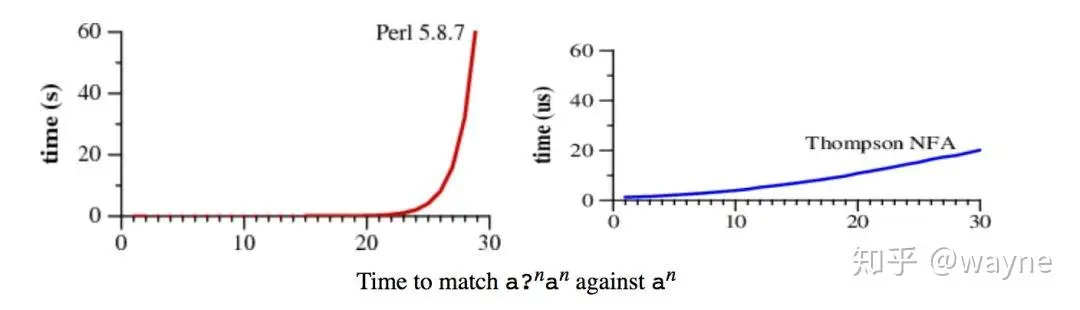
The code is as follows, you can try it yourself if you are interested.
time perl -e 'if ("aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa" =~ /a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/) {print("hit");}'
40.80s user 0.00s system 99% cpu 40.800 total
It takes 40.8 seconds to run this canonical, during which time the CPU is 99%.
With RE2, the contrast is very clear.
time perl -e 'use re::engine::RE2; if ("aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa" =~ /a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/) {print(" hit");}'
perl -e 0.00s user 0.00s system 34% cpu 0.011 total
- Intel Hyperscan
Intel Hyperscan is also a regular engine similar to RE2, and there are libraries for Perl, Python and other languages, so it is not too difficult to get started.
Only in accordance with Intel's practice, more platform binding, can only run in x86.
If there is a unique benefit, it may be the ability to work better with Intel's instruction set and hardware, with performance improvements, such as combining it with its own DPDK.
Snort, an open source network intrusion detection tool, also uses Hyperscan to replace the previous regular engine, so students familiar with Snort can try it.
Extensions
Here are a few papers on regular expressions, which can be read as an extension if you are interested.
-
SlowFuzz: Automated Domain-Independent Detection of Algorithmic Complexity Vulnerabilities: https://arxiv.org/pdf/1708.08437.pdf
-
Static Analysis for Regular Expression Exponential Runtime via Substructural Logics: https://arxiv.org/abs/1405.7058.pdf
-
ReScue: Crafting Regular Expression DoS Attacks: https://dl.acm.org/doi/10.1145/3238147.3238159
-
Regular Expression Matching Can Be Simple And Fast: https://swtch.com/~rsc/regexp/regexp1.html