Why Beike, the Popular Housing Platform, Chooses Apache APISIX
Hui Wang
December 11, 2020
Hi, I am Hui Wang, responsible for developing the API gateway system at Ke Holdings (Beike), a leading integrated online and offline platform for housing transactions and services in China. Beike uses Apache APISIX as the API gateway on the production system. As a data-driven company, millions of production traffic would go through the API gateway daily, and Apache APISIX could provide stable and outstanding performance. Recently Apache APISIX just joined the Apache incubator, I would like to take this opportunity to share the reason why we chose Apache APISIX at the very beginning and some experiences while using it.
Kong or Apache APISIX
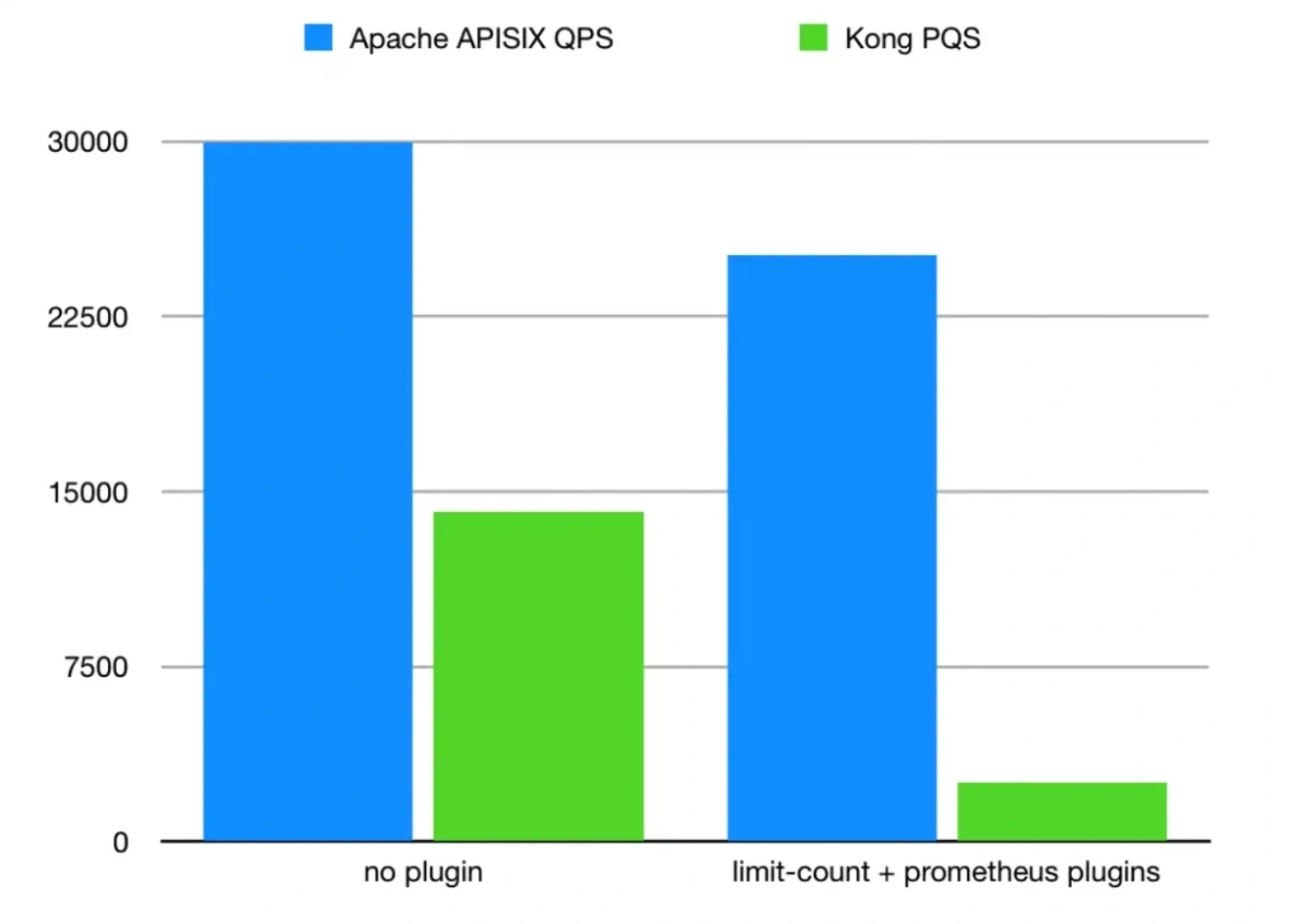
For the technical requirements of the gateway, first of all, the gateway must have excellent performance and the ability to support the access of significant traffic. Furthermore, it should also be stable, with a zero error rate.
The vendor selection principle is reconstructing a more stable version based on or learned from other open-source projects to access more considerable traffic. After evaluating the pros and cons, I discussed this idea with my supervisor, and we decided to kick off this project. The first choice that came to my mind was Kong, another famous open-source gateway.
After browsing Kong’s official website and reading some related articles, I thought Kong was a suitable option since it could meet most of the users' needs, and the performance was also very stable. I immediately git cloned the code and started reading it. However, I felt pretty confused even after several days of investigating. I guess I figured out the reason why Kong has such a huge code base, which is that it needs to provide tons of functionalities.
Suddenly, several questions revolved in my mind. How long can I fully understand Kong? How long does it take to build a project that suits all requirements? Do I need all these functionalities Kong provides?
A few days before, the API gateway Apache APISIX version 0.5 was released. With a learning attitude, I quickly looked at this open-source project and surprisingly found that Yuansheng Wang and Ming Wen, two experts in the field of API, together developed it. I could not refuse this product based on these experts’ endorsements.
As the open source project was born not long, the supported functionalities of Apache APISIX are also pretty limited. However, all essential functions, such as dynamic load balancing, circuit breaker, identity authentication, and rate limiting, have already been implemented. Meanwhile, a relative small code base also reduces the learning cost. Compared to Kong, I could announce the victory of Apache APISIX. Apache APISIX is more suitable for my current situation since it could meet my initial feature plan without any concerns about unneeded functionalities.
However, the most critical problem is that Apache APISIX's performance might be shortboard due to its limited open source time. Compared stress test results with Kong under the same test environment, Apache APISIX ultimately beat Kong. However, it is not fair for Kong since Kong is much heavier and much more complex. On the other hand, there is no difference in my use case since all needed functionalities are provided in Apache APISIX. According to the performance test report of Apache APISIX, a single-core CPU can reach 24k QPS, while the latency is only 0.7 milliseconds.
In summary, I chose Apache APISIX for the following reasons:
- On the premise that it can meet all needs of the project, the learning cost of Apache APISIX is low
- Kong has a large code base, which brings it challenging to maintain the codes
- Apache APISIX authors are more active in the OpenResty community, with could provide better code quality
- The most important thing is to quickly resolve any questions by directly communicating with the authors
The reasons for the APISIX provided by the official website are shown in the following figure:

What capabilities can Apache APISIX provide
- Hot Updates and Hot Plugins
- Dynamic load balancing
- Active and passive health check
- Circuit Breaking
- Authentication
- Rate limiter
- gRPC protocol conversion
- Dynamic TCP/UDP, gRPC, WebSocket, MQTT broker
- Dashboard
- Prohibited and Permitted List
- Serverless
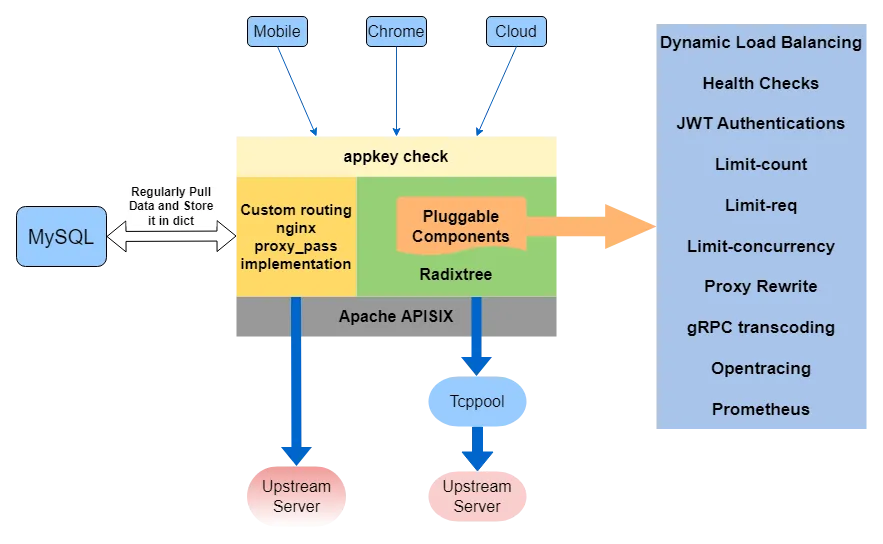
Apache APISIX has been released in nearly ten versions, supporting far more functionalities than these listed ones. The architecture diagram is drawn according to the business situation, as follows:
The story of how we integrated APISIX
After a few days of code reading, I have a basic understanding of Apache APISIX, but a question popped up: I have never developed any open-source projects. How could I accomplish it? I created three different branches locally, one Apache APISIX branch points to the upstream open source repository, another branch dev is used for regular business iteration, and the last main branch is used for online upgrades.
After two weeks of hard work, my project finally has some fundamental structures. It is time to examine the result; that is how we started the stress test stage. The service is deployed on Tencent Cloud with 8 Core and 32 GB memory servers, and the upstream is a regular cloud production environment, so it cannot be tested too hard. The performance report is as follows:
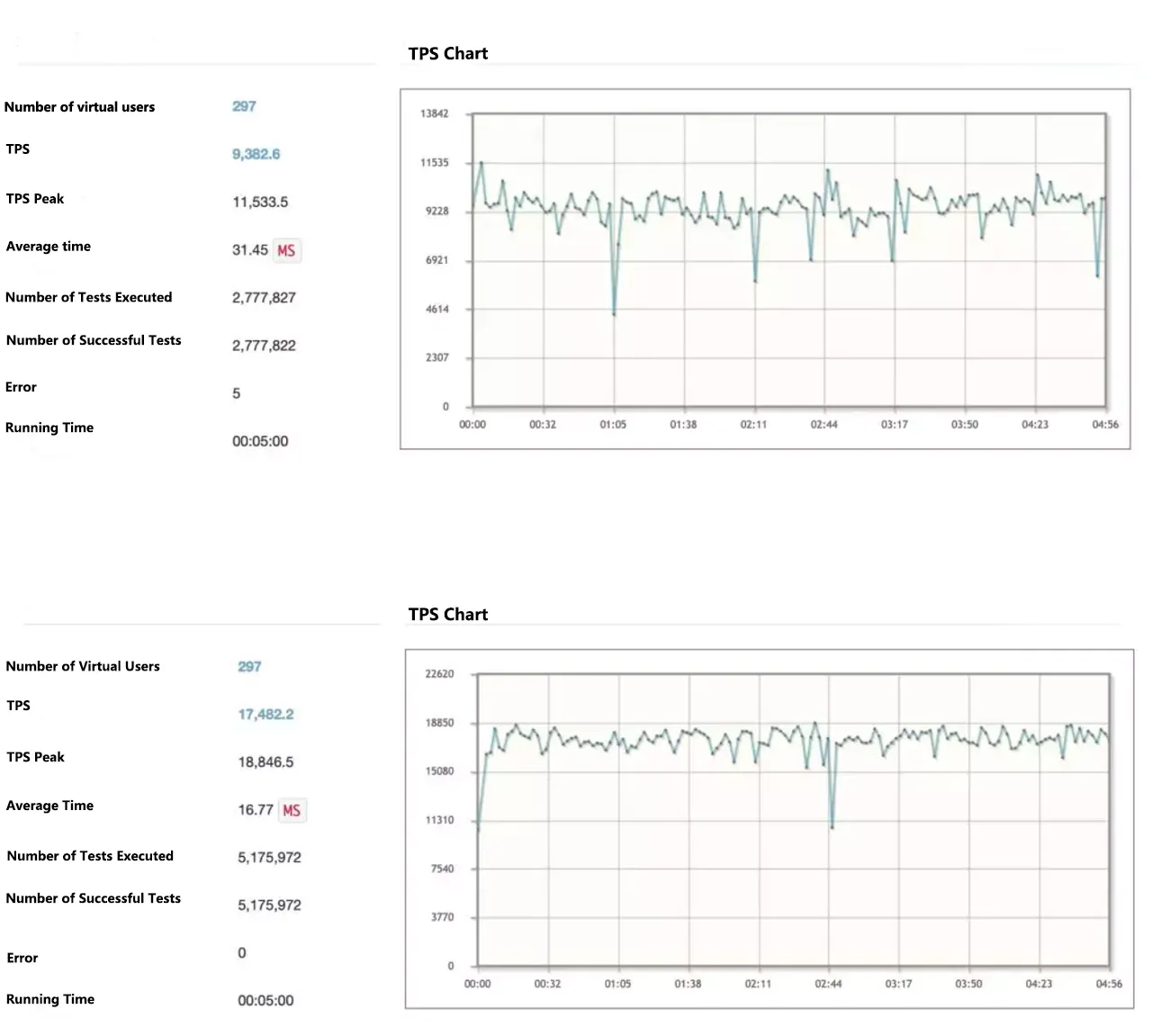
Performance report summary: The interface time consumption is reduced by 47%, no errors are raised, and the stability is improved. The TPS peak value is increased by 82%, no errors are raised, and the stability is improved.
The development environment is ready, and we started studying cloud deployment. Apache APISIX supports many installation methods: Docker, RPM Package, Luarocks, and source codes. The bad news is that nothing is allowed to be installed in the cloud environment, and the source code can only be placed in a fixed route path. Therefore many Apache APISIX features would not be supported since they are developed based on OpenResty 1.15.8. What could I do? Compiled files are generated in the code repository, it has to be compiled under some specified directory, and you cannot use the static binding of PCRE, which costs us 1-2 days. At last, we adjusted the grey release; the traffic rose from 2% to total volume within several weeks. Fortunately, everything went successfully in the end.
After several weeks of monitoring, the online service is relatively stable. Many functionalities of Apache APISIX 0.5 have to be implemented through API interface calls. The request parameters are prone to syntax errors, and there is no intuitive and convenient page. Apart from that, our business scenario needs to have the functionality of probing upstream services. It is such a coincidence that Apache APISIX version 0.7 has just been released, and version 0.7 supports console and upstream service exploration, which is exactly what we need right now. What great news! We have to upgrade!
The Apache APISIX branch is easy to upgrade to 0.7, but how could we merge the code? The code changes between these two versions are enormous. I try to merge them first, but there are too many conflicts, and we are at such an dangerous pace. The standard method of resolving conflicts is unrealistic, which could cause tons of hidden bugs. Is there any efficient solution? I searched online and found the shortcut methods: git checkout –ours and git checkout –theirs (please search it if you have not used it), and completed the upgrade from APISIX 0.5 to 0.7 in a few minutes. Of course, it should also thank the robustness of APISIX code, which lets me only need to add business plugins without any coupling.
Since Apache APISIX 0.7 version provides a console, no need to spell JSON anymore. I quickly examined the health check, and there was no problem initially, and I could perceive the status of the upstream service. However, when I checked the logs of the upstream service, I found that after several reboots, the frequency of the health check kept increasing. I guess there might be a bug in the health check. After reading the source code, I found out checker for each router is not globally unique. Instead, every work has a checker. We could resolve this issue by using the same name for all created work. Even if it is a minor fix, a hot-fix PR is necessary.
I upgraded the online business APISIX to 0.7 and monitored the service resource usage. After all, it was a significant version change, and I felt nothing for the first few hours, similar to the last 0.5 change. I will take a second look when I get off work. It seems that the memory usage is not correct. The 0.5 version has been relatively stable, but the 0.7 version seems to have memory leaks. Since memory usage is growing very slowly, I decided to monitor it for a whole night. The next day, I compared the monitored data, determined that there was a memory leak, and quickly rolled back to the previous version. After everything was done, I provided feedback to Yuan Sheng about this issue. According to the scenario I described, I found the problem through stress testing. It was a problem with the radix tree. The same issue never occurred after I upgraded the dependencies since Yuan Sheng released the new version of the radix tree.
After relaunching the project, Apache APISIX 0.7 version could still give me surprises from time to time. The routing dependency used in Apache APISIX 0.5 version was libr3, while Apache APISIX 0.7 used the radix tree, which performs better. CPU usage and memory usage percentages both declined. In Apache APISIX 0.5, the CPU usage is 1-10%, and the memory is 0.1%. In Apache APISIX 0.7, the CPU usage is reduced to 1-2%, and the memory is less than 0.1%, which is excellent.
Future Plan
Apache APISIX has been launched for two months, and there are neither failures nor errors. This is just the beginning, and we can do much more in the future to show more capabilities to service providers. The gateway provides a reverse proxy and helps some teams that do not have time to develop functions to ensure service stability, including services such as current limiting, circuit breaker, monitoring, and access platforms.
Finally, I would like to thank Yuan Sheng and Wen Ming for providing such excellent products and the Apache APISIX community for the contributed iterative functionalities. Now the daily traffic of the gateway has exceeded 100 million, and there is no performance problem. Thank you for your time and attention!