Apache APISIX 现有基于 HTTP 的 etcd 操作的局限性
etcd 在 2.x 版本的时候,对外暴露的是 HTTP 1 (以下简称 HTTP)的接口。etcd 升级到 3.x 版本后,其对外 API 的协议从普通的 HTTP 切换到了 gRPC。为了兼顾那些不能使用 gRPC 的特殊群体,etcd 通过 gRPC-gateway 的方式代理 HTTP 请求,以 gRPC 形式去访问新的 gRPC API。
APISIX 开始用 etcd 的时候,用的是 etcd v2 的 API。从 2020 年的 APISIX 2.0 版本起,我们把要求的 etcd 版本升级到 3.x。etcd 对 HTTP 的兼容帮了我们很大的忙,这样就不用花很大心思去重新实现操作 etcd 的方式了,只需调整下新的一组 API 的调用方式和响应处理。然而在实践过程中,我们也发现了跟 etcd 的 HTTP API 相关的一些问题。事实上,拥有 gRPC-gateway 并不意味着能够完美支持 HTTP 访问,这里还是有些细微的差别。
我把过去几年来在 etcd 上遇到的相关问题列了一下:
- 在某些情况下,etcd 默认没有启用 gRPC-gateway。由于维护者的疏忽,在某些平台上,etcd 在配置时没有默认启用 gRPC-gateway,所以我们不得不在文档中添加一个注释,以检查 etcd 当前是否启用了 gRPC-gateway。具体可参考 https://github.com/apache/apisix/pull/2940。
- gRPC 默认将响应限制在 4MB 以内。etcd 在其提供的 sdk 中解除了这一限制,但忘记了在 gRPC-gateway 中解除。因此,官方的 etcdctl(使用了 sdk)工作正常,但 APISIX 却无法正常访问。具体可参考 https://github.com/etcd-io/etcd/issues/12576。
- 同样的问题 —— 这次是发生在同一连接的最大请求数上。Go 的 HTTP2 实现有一个 MaxConcurrentStreams的配置,控制单个客户端能同时发送的请求数,默认是 250。正常情况下,哪个客户端会同时发送超过 250 个请求呢?所以 etcd 一直沿用这一配置。然而 gRPC-gateway 这个代理所有 HTTP 请求到本机的 gRPC 接口的“客户端”,却有可能超出这一限制。具体可参考 https://github.com/etcd-io/etcd/issues/14185。
- etcd 在开启 mTLS 后,会用同一个证书来作为 gRPC-gateway 的服务端证书,兼 gRPC-gateway 访问 gRPC 接口时的客户端证书。如果该证书上启用了 server auth 的拓展,但是没有启用 client auth 的拓展,那么会导致证书检验出错。直接用 etcdctl 访问不会有这个问题,因为该证书在这种情况下不会作为客户端证书使用。具体可参考 https://github.com/etcd-io/etcd/issues/9785。
- etcd 在开启 mTLS 后,允许针对证书里面的用户信息配置安全策略。如上所述,gRPC-gateway 在访问 gRPC 接口时用的是固定的一个客户端证书,而非一开始访问 HTTP 接口所用的证书信息。这个功能自然就没办法正确工作了。具体可参考 https://github.com/apache/apisix/issues/5608。
造成上述问题的原因可以归纳为两点:
- gRPC-gateway(或许还有其他将 HTTP 转换为 gRPC 的尝试)并不是万能的。
- etcd 的开发者没有对 HTTP 到 gRPC 的路径给予足够的重视。毕竟他们最大的用户,Kubernetes,并不会使用它。
要想从本源上解决这一问题,我们需要直接通过 gRPC 来操作 etcd,这样就不用走为了兼容而保留的 HTTP 路径。
克服各种挑战,迁移到 gRPC
跳过 lua-protobuf 的 bug
在迁移过程中,我们遇到的第一个问题,是一个预想不到的第三方库的 bug。像绝大多数 OpenResty 应用一样,我们采用 lua-protobuf 来完成 protobuf 的 decode/encode。在引入 etcd 的 proto 文件之后,我们发现 Lua 代码中会出现偶发的奔溃,报错说遇到了 "table overflow"。由于这个崩溃不能稳定复现,我的第一反应是寻找最小可复现的例子。但是有趣的是,如果单独使用 etcd 的 proto 文件,那么无论如何都无法复现该问题。这个崩溃似乎只能出现在 APISIX 运行的时候,真是神奇。通过一些调试,我把问题锁定到了 lua-protobuf 在解析 proto 文件的 oneof 字段时的逻辑。lua-protobuf 在解析时会尝试预分配 table 大小,而分配的大小是按照某个值计算过来的。有一定几率,这个值会是个负数,然后 LuaJIT 在分配时把这个数转成很大的正数,结果导致了 "table overflow" 错误。我向作者报告了该问题,并在我们内部维护了一个带 workaround 的 fork。lua-protobuf 作者反应很迅速,次日就提供了一个修复,并在几天后发布了新的版本。原来 lua-protobuf 在清理不再使用的 proto 文件时,曾经漏了减少某些字段,导致在后续处理 oneof 时会得到一个不合理的负数。之所以是偶现的问题,之所以无法在单独使用 etcd 的 proto 文件时复现,都是因为少了“清理”这一关键的前置操作。
向 HTTP 的行为对齐
世间鲜有东西是从头开始的,往往不得不从当前继承一些负担。在迁移过程中,我发现一个问题,就是现有的 API 返回的并不是一个简单的请求执行结果,而是个包含 status 和 body 的 HTTP response,然后由调用方去处理这个 HTTP response。这么一来,gRPC 的响应结果就需要套上一个 HTTP response 的壳。不然调用方就需要改动很多处地方来适配新的响应格式。尤其考虑到旧的基于 HTTP 的 etcd 操作也需要同时支持,虽然兼容 HTTP response 的套壳行为并非我所欲,但是还是得向现实低头妥协。除了要加壳之外,我们还需要对 gRPC 响应做一些裁剪。比如在没有对应数据时,HTTP 不会返回任何数据,而 gRPC 会返回一个空 table。裁剪结果嘛,自然都是向 HTTP 的行为靠齐。
从短连接到长连接
在基于 HTTP 的 etcd 操作中,APISIX 都是采用短连接,所以不需要考虑诸如连接管理的问题。反正用的时候发起新连接,用完 close 即可。但 gRPC 就不能这么操作了。迁移到 gRPC 的一大目的就是为了达到多路复用,如果每次操作都创建新的 gRPC 连接,那么就无从实现这一目的。这里需要感谢 gRPC 功能的内核 gRPC-go 自带了连接管理的能力,面对连接中断可以自动重连。这样判断是否需要复用连接,在 APISIX 这一层就只需考虑业务需求。APISIX 的 etcd 操作可以分为两类,一类是去对 etcd 的数据做增删改查;另一类是从控制面同步配置。虽然理论上这两种 etcd 操作可以共享同一个 gRPC 连接,但是出于权责划分的考虑,我们决定把它们分成两个连接。对于增删改查的连接,由于 APISIX 启动时和启动后的连接需要分开对待,所以在获取新的连接时加了个判断,如果当前连接是启动时创建且目前需要的是启动后的连接,那么会关闭当前连接并创建新的连接。对于配置同步,我开发了新的同步方式,让每一种资源都采用当前连接下面的一个 stream 来 watch etcd。
迁移到 gRPC 后,我们得到了什么样的好处
迁移到 gRPC 后,一个显而易见的好处是操作 etcd 所需的连接大大减少。原来通过 HTTP 操作 etcd 时,APISIX 都是采用短连接。而且在同步配置时,每种资源都会有一个单独的连接。在切换到 gRPC 之后,我们可以用上 gRPC 的多路复用功能,每个资源都只使用单个 stream,而不是完整的连接。这样一来,连接数就不再随着资源数的增加而增加。考虑到 APISIX 的后续开发将会引入更多的资源类型,比如当前最新的 3.1 版就新增了 secrets,采用 gRPC 带来的连接数的减少将会越来越明显。
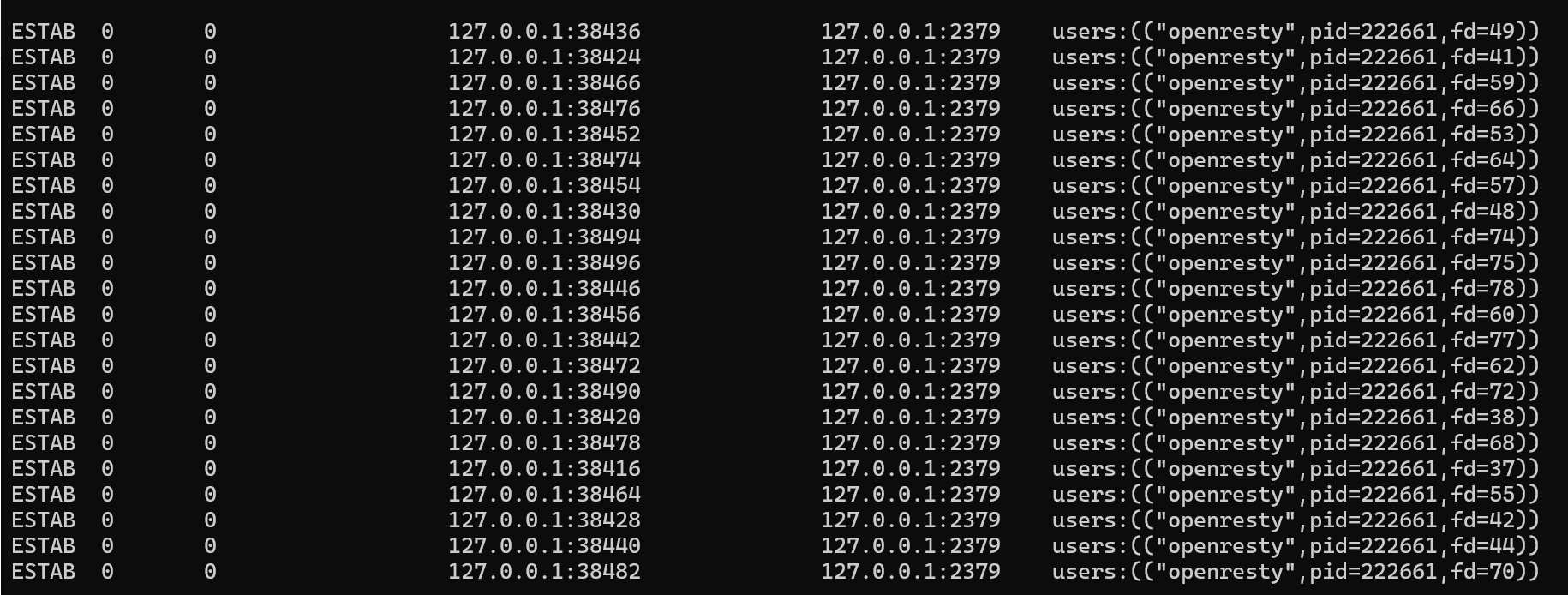
使用 gRPC 同步时,每个进程只有一条用于配置同步的连接(如果开启了 stream 子系统,那么是两条)。在下图中我们能看到两个进程共有四个连接,其中两个是配置同步,还有一个连接由 Admin API 使用,剩下一个连接是特权 agent 上报 server info。

作为对比,下图是保持其他配置不变,使用原有的配置同步方式所需的连接数。具体有多少我就不数了。另外这些连接还是短连接。
这两个配置的区别,仅在于是否启用了 gRPC 来做 etcd 操作:
1 etcd:
2 use_grpc: true
3 host:
4 - "http://127.0.0.1:2379"
5 prefix: "/apisix"
6 ...除了连接数的减少外,使用 gRPC 来直接访问 etcd 而非绕道 gRPC-gateway,能够解决文中一开始提到的关于 mTLS 鉴权等一系列受限于架构的问题。此外,我们也相信使用 gRPC 后遇到更少的问题,因为 Kubernetes 就是通过 gRPC 来操作 etcd 的,如果有问题,在 Kubernetes 社区应该会更早地发现。
当然,作为一个新生事物,APISIX 通过 gRPC 操作 etcd 时不免会有一些新的问题。毕竟我们之所以发现了许多 HTTP 路径下的问题,是因为我们对 HTTP 用得比较多。所以目前我们还是默认采用原有的基于 HTTP 的方式来操作 etcd。不过用户可以自行在 config.yaml 中配置 etcd 下的 use_grpc 为 true,尝试一下新的方式是否更优。我们也会听取各路反馈意见,继续完善基于 gRPC 的 etcd 操作,并持续积累更多的经验。在后续的某个时候,当我们判断新方式足够成熟时,就会把它确定为默认的途径。