作者杨文斌,Zoom 云原生架构师。
最近几年,线上会议和远程办公的趋势逐渐流行,应运而生了一批家喻户晓的远程会议软件。其中 Zoom 作为活跃于全球范围内的应用,已成为目前居家办公、线上教学和社交场景的必备会议工具。
业务发展的同时,Zoom 也一直在探索业界前沿技术,向云原生方向演进。在 API 网关方面,开始逐步从传统的 NGINX 方案向 Apache APISIX 云原生网关推进;在应用交付方面,Zoom 参考了 OAM 理念,打造了自研的 YAM(Yet Another Application Model)持续交付引擎。
本文将主要介绍 YAM 持续交付引擎的设计,以及与 Apache APISIX Ingress 的无缝集成,实现 Kubernetes 集群大量微服务的全自动化 API 生命周期管理。
网关的选型与迁移
与大多数 IT 企业类似,Zoom 之前的网关采用了业界主流的 NGINX 网关方案,但随着业务的快速发展和微服务数量的增多,当前 NGINX 方案的局限性日趋明显。
比如之前不同业务线都需要各自维护 NGINX,多个 NGINX 的配置代码超过数千行,难以维护。同时将其直接部署在云服务器上时,NGINX 不具备快速扩缩容能力。
同时公司内一些业务开始向 Ingress Controller 演化,API 网关团队也在一些主流开源方案中进行调研,经过对实际业务在 NGINX 配置的模拟迁移和分析,以及大量性能压测和插件生态对比,最终 Zoom 选择了APISIX Ingress,开始向更先进的云原生网关方向探索。
选型过程中 Zoom 也针对自己的业务场景进行了如下考虑:
比如 Zoom 非常重视客户隐私和服务安全性,需要在会议室、话机等业务中大量使用双向 TLS 验证和加密, APISIX 可以非常方便进行 mTLS 的配置和使用;
在服务稳定性方面,后端服务需要做到跨区域的异地多活,APISIX 开放的插件生态和便捷的插件开发流程,刚好可以满足迁移 NGINX 中存在的大量异地多活逻辑的需求。
网关选型完成后,团队又面临了一个新的挑战,即如何将数百个服务的 API 网关配置迁移到 APISIX 中呢?正好,Zoom 基础设施团队开发了一款云原生应用交付引擎 YAM,它致力于打造最简洁的端到端应用交付体验,可以很大程度上减轻从 nginx.conf 和其他 Ingress 转换到 APISIX 的迁移成本。
YAM 引擎是什么?
YAM 引擎是一个端到端的应用交付引擎,实现了使用一个模型进行声明所有应用交付需求、一行命令编排和执行所有持续交付步骤。
模型交付流程
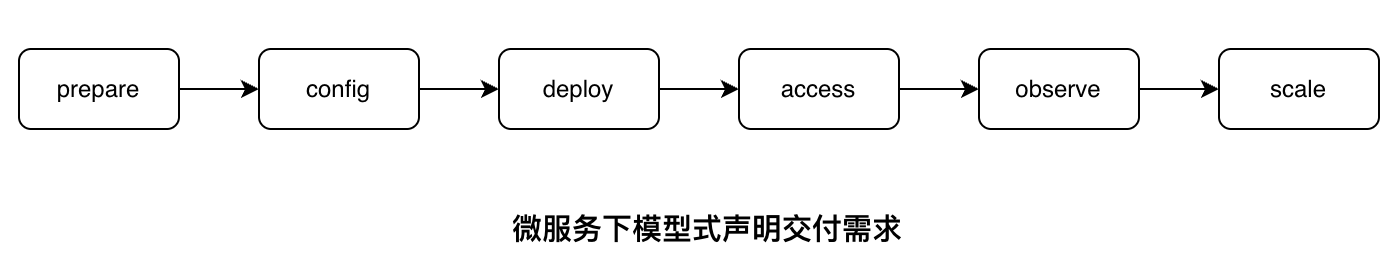
YAM 引擎的模型式声明主要包含以下 6 个环节,每个环节都由 1 个或多个插件实现,可任意扩展模型定义:
Prepare:准备预置资源,包括基础设施、中间件、云服务资源等;
Config:准备应用程序所需的配置文件和密钥;
Deploy:在云原生场景下使用 K8s 进行部署 (包括容器、容器镜像、参数、版本和实例等信息);
Access:部署如需外部访问,创建 Kubernetes Service,自动配置 Apache APISIX Ingress 的路由规则;
Observe:进行可观测性相关配置,比如监控、告警、日志和链路追踪等场景;
Scale:通过监控指标声明 KEDA 的动态扩缩容规则。
为何开发新的 CD 引擎
云原生和微服务趋势下,SaaS 型企业以及一些互联网企业通常会遇到如下的「三多」问题:
微服务数量多。由于 Zoom 的业务和开发团队快速增长,因此需要交付的后端服务数量开始成倍增加,数量过百。
部署环境多。SaaS 类企业经常会遇到客户需要部署专有云、私有云和多云的场景。而 Zoom 业务服务遍布全球,因此也存在异构云环境和环境总数多的技术挑战。
中间件和基础设施多。中大型 IT 企业,一般都会有独立的基础设施和中间件团队,比如:API 网关、配置中心、密钥管理、日志、监控告警、数据库、消息队列等。在 Zoom 内部,这些基础设施是全球分布的研发团队进行维护。如何把这些复杂的中间件和基础设施,整合到持续交付的流程中,也是一个巨大的挑战。
基于上述问题,Zoom 在进行底层交付引擎打造过程中,调研了一些主流解决方案,从 Helm 方案迭代到目前自研的 YAM 方案,后续 YAM 方案也会进行开源。
多视角设计思路
在 OAM 分离了应用视角和基础设施视角两个维度的基础上,YAM 对其进行了扩展,实现了四个维度的关注点分离。将整个软件开发交付的生命周期划分为以下几个角色(如下图左侧人物):
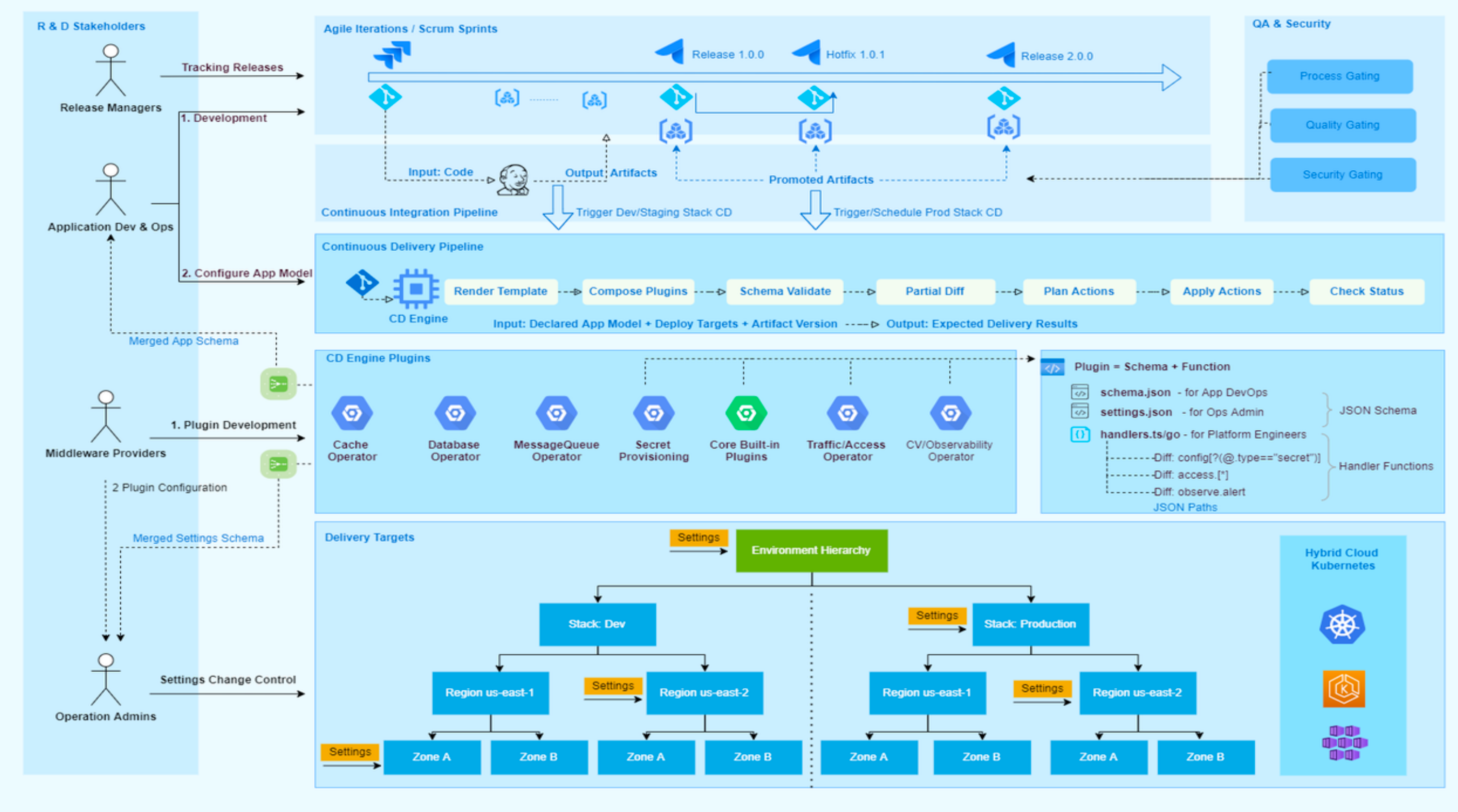
项目管理人员(时间维度):关注研发迭代,在迭代对应的时间轴线上,管理迭代发布进度和人员效能。
应用开发人员(应用维度):关注业务功能的开发实现,更多聚焦在上层业务中,希望打造开箱即用的基础设施。
中间件维护人员(基础设施维度):对应用开发提供底层的支持,保障基础设施的稳定性,需要对某一类基础设施进行集中控制。
环境管理人员(空间维度):主要是去统一管控所有的交付环境、权限和资源配额等。
以上四个视角,就已经把软件交付的相关者和基本需求完全涵盖了。
APISIX 网关配置的多视角案例
接下来,我们以 APISIX 作为案例,将其代入到上述四个视角中,分析如何满足各个视角下,对 API 网关配置自动化管理的不同需求。
项目管理视角
在项目管理侧,相关人员主要关注以下问题。比如每个迭代版本中新上线了哪些 API ?新上线的 API 有没有风险?对于复杂项目出现多个迭代并行发布时,不同迭代版本上线到不同环境是否会产生冲突?
如何实现这些需求呢?Zoom 内部采用的技术方案是采用 GitOps 工作流,把 API 网关的配置内置到应用交付模型中,随着 Git 分支的创建和合并,让 APISIX 的配置变更完全融入到迭代的工作流中。这样在项目管理视角下,就无需处理多迭代并行时,上下游系统匹配变更的时间差问题。
1# Git仓库的app.yaml片段
2deploy:
3 type: Deployment
4 replicas: ~{ replicas, 2 }
5 version: "latest"
6 containers:
7 - name: my-app
8 image: "busybox"
9 command: "echo 'Demo' && sleep 99d"
10access:
11 - protocol: https
12 host: my-domain.my-org.com
13 cert: my-tls-cert
14 apisix:
15 routes:
16 http:
17 - name: my-api
18 authentication:
19 # ......
20 match:
21 paths:
22 - /my-api/*可以看到在抽象出来的应用交付模型中,APISIX 路由规则的定义与 Deploy 和其他环节融合到了一起,将变更控制完全交给 Git 托管。实现了在时间维度上的统一,从而将发布管理简化成 Git 工作流的管理。
应用开发视角
在应用开发视角,开发人员则主要关注 API 的路由和鉴权能力,因为这两类是与业务服务强相关的,应该让开发者进行自助填写,实现自动生效。
从上文的代码片段中可知,开发者仅仅定义了 Authentication 和 Match 两个部分。即开发者并不需要知道底层逻辑会先翻译成 Kubernetes Deployment 和 Service、调用平台 API 检查和校验路径正确性、再翻译成 ApisixRoute 对象等等这一系列复杂的过程。
从开发者视角看到的结果是,在 Git 里定义了一个新的 API,这样下次构建部署这个分支时,所有的配置都会自动生效了。这个过程中,将不涉及任何卡点和跨部门的摩擦,在网关上添加配置比写代码还要简单。
环境管理视角
环境管控视角的复杂需求,大部分面向 C 端的企业可能不会遇到。而在 toB 场景中,就经常需要考虑在一些私有云、专有云和混合云场景下的交付问题。比如在某个专有云环境中,控制权不在网关团队,该环境使用的是 NGINX Ingress Controller,而其他环境又全部迁移到了 APISIX Ingress Controller 时,如何从环境管控上对开发者屏蔽差异。
YAM 引擎为基础设施和环境管控视角提供了相关配置,这样管理人员可以切面化地控制某些异构非对等环境的差异,对所有部署到该环境的服务全部生效,避免了环境差异对于开发运维带来的认知负担和特殊部署操作。
例如下述这段示例的引擎配置就可以实现:对于某些环境禁止链路追踪、将 ApisixRoute 对象转换成原生 Ingress 对象 + NGINX Ingress 的 Annotation、使用不同的镜像拉取密钥。
1- envPatterns:
2 - prod/private-cloud/**
3 disabledPlugins:
4 - "some-tracing-plugin-in-public-cloud"
5 settings:
6 "@yam-plugin/ingress-apisix":
7 downcastToIngress: true
8 apisixRouteAnnotations:
9 k8s.apisix.apache.org/ingress.class: ~{my-tenant}
10 "@yam-plugin/core-deploy":
11 imagePullSecrets: some-secret-in-private-cloud另一个环境管控的场景是当有多个业务线都在使用 APISIX 环境,这时就需要进行多租户的隔离。同样,这样的规则也可以在引擎的配置中统一描述。比如 APISIX Ingress 提供的 Annotation 选择器,可以实现不同的 ApisixRoute 对象被不同的 APISIX Ingress Controller 实例拾取。
中间件和基础设施视角
最后一个视角则是 API 网关团队自身的视角,即他们需要管控所有的 APISIX 实例,切面化配置安全策略、异地多活的实现等等。
同样,每个 YAM 插件都给基础设施人员提供了配置项,在 ingress-apisix 插件中,有一个 defaultPlugins 属性,API 网关团队对其进行配置后,将对所有服务生效。非常适合基于此进行统一的安全与风控策略。
比如下方代码示例中,可以默认添加 requeist-id 插件,让所有服务自动添加 Tracing ID,在所有服务中统一 Tracing 的规范。
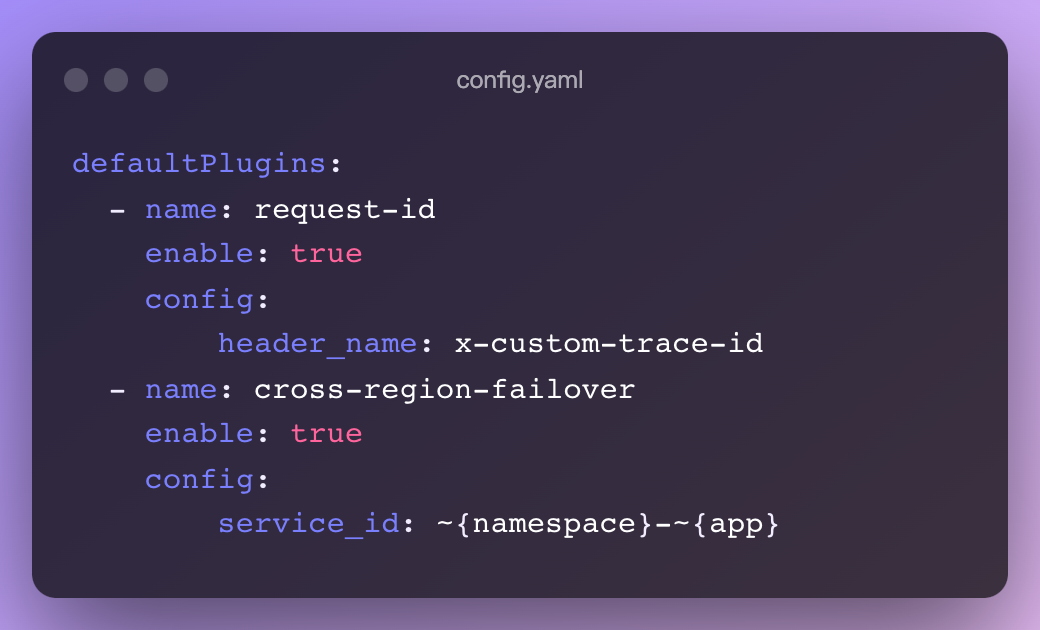
其次就是上图示例中批量给服务添加自研的异地多活插件 cross-region-failover,让应用开发无需关心 API 网关的可用性问题。这个案例中,中间件团队只需填写引擎配置,反向引用一些应用模型的元数据参数,让各个上下游能够统一服务名等元数据。让基础设施团队更加专注在基础设施的迭代上,而不是花费大量时间处理业务服务的工单。
总结与思考
在持续交付领域,业界主流方向都在往 Everything as Code 进行演进,那 EaC 的含义究竟是什么?
从表层来看,Everything as Code 包括了 Infrastructure as Code,Pipeline as Code,Policy as Code 等等。EaC 就是把一切变更都以代码的形式描述在 Git 这样的版本控制系统中,用 Git Branch/Tag 把变更拉到同一根时间轴上,用配置管理语言编码出可追溯的软件交付终态,最终实现整个软件供应链的 "Single Source of Truth"。
从底层来看,Everything as Code 要求平台工程师构建出一套基于声明式 API 的自助式持续交付方案,以及可以承载这些 Code 的交付平台,使得应用交付的任何环节都可被声明式地描述、编排和执行。
EaC 对基础设施层提出了很大的挑战,每个环节都正在被重构。于是,基于云原生繁荣的生态和一批云原生开源项目开始涌现,这些新兴方案以声明式 API 和代码化的方式互相整合,正在逐渐颠覆传统解决方案。