引言:从分散流量到智能治理的转折点
自 2025 年初,在一家全球领先的家电巨头公司内部,多个业务线引入了众多大语言模型(LLM)——研发部门需要代码助手提升效率,营销团队侧重于内容生成,智能产品团队希望将对话能力整合进家电终端。模型的种类在短时间内急剧增加,既包括自建的 DeepSeek、Qwen,也有来自多家云服务商的专有模型。
然而,这一快速扩张很快暴露出新的瓶颈:推理流量分散、调度混乱、运维成本攀升、稳定性不可控。
基础架构团队意识到,他们需要一个能够从流量层统一管控、动态调度的中枢系统——一个为 AI 而生的网关。
于是,该企业开始与 API7 团队合作,共同构建企业级的 AI Agent 流量管理和调度平台。这不仅是一场关于网关技术的升级,更是一次面向 AI 时代的架构重塑。
挑战:多模型、多租户、混合云的复杂度
在该家电巨头的 AI 实践中,挑战主要集中在三个层面:
1. 稳定性保障
- 模型快速迭代、服务多样化,如何确保每次请求的稳定代理与快速恢复?
- 在不同厂商的 LLM 服务之间,如何做到零中断切换?
2. 多租户隔离
- 各业务部门都有独立的 AI Agent,一旦某租户的任务失控,必须实现资源与故障隔离,避免“牵一发而动全身”。
3. 智能调度
- 采用混合云架构,自建模型与云端模型共存。面对动态负载,缺乏一个能实时感知健康度、自动优化路由的系统。
这些问题共同指向一个核心需求:AI 流量必须被统一治理、可视化监控、智能调度。
系统设计:AI 网关的核心架构
该企业选择在现有 API 网关之上,构建一层 AI 网关能力,使其成为统一的智能流量中枢。
从整体上看,系统分为三个核心层面:
- 接入层:提供统一入口,负责协议转换、身份鉴权与限流控制。
- 治理层:基于插件机制实现动态路由、降级、故障检测、内容过滤等核心能力。
- 调度层:结合健康检查与实时负载信息,完成在自建与云端模型之间的自动切换。

在 AI 网关上,部分 AI 模型版本迭代较快,存在稳定性风险,例如请求格式不当可能引发模型死循环、持续异常输出或生成不合理内容。为此,该企业内部技术团队基于 APISIX AI 网关的插件扩展机制,通过请求体改写与防御等自定义插件以及灵活配置的方式,对请求和响应内容进行干预和过滤,以保障服务的可靠性与输出质量。
选择 AI 网关的关键指标
在构建 AI 能力平台的过程中,网关选型对整体架构的影响颇为重要。该企业主要基于以下几个核心维度进行考量:
- 生产级稳定性:稳定性是核心。保障用户的服务稳定性,即使在模型出现波动时,让业务能不间断运转是最核心的诉求。
- 持续演进的技术能力:AI 技术迭代迅猛,网关必须保持快速更新节奏,及时适配新的模型协议与交互方式。选择的网关需要能够跟上技术发展趋势,避免成为业务创新的瓶颈。
- 标准化的可复用架构:成熟、可复用的架构是另一个要点,提供标准的 API 管理和扩展接口,并符合主流技术标准与最佳实践。APISIX AI 网关的可扩展性是一大亮点,这直接决定了系统与现有技术栈的集成成本,以及未来融入更广阔 AI 生态的平滑程度。
AI 流量的精细化治理与多租户隔离
场景 1:混合模型的自动 fallback
在实际使用中,该头部家电企业对关键模型(A 模型)采用混合部署模式:一部分服务自建于私有机房,作为主力承载核心流量;同时,在公有云上按量付费使用此模型作为 Plan B。
所有请求默认优先导向自建服务。当自建服务因突发流量或业务高峰导致性能瓶颈或不可用时,网关会基于预设的 token 限流策略与实时健康检查,自动、无损地将请求切换至云端服务,实现平滑回退。待自建服务恢复后,流量再自动回流。
1curl "http://127.0.0.1:9180/apisix/admin/routes" -X PUT \
2 -H "X-API-KEY: ${ADMIN_API_KEY}" \
3 -d '{
4 "id": "ai-proxy-multi-route",
5 "uri": "/anything",
6 "methods": ["POST"],
7 "plugins": {
8 "ai-proxy-multi": {
9 "balancer": {
10 "algorithm": "roundrobin",
11 "hash_on": "vars"
12 },
13 "fallback_strategy": "instance_health_and_rate_limiting",
14 "instances": [
15 {
16 "auth": {
17 "header": {
18 "Authorization": "Bearer {ALIYUN_API_KEY}"
19 }
20 },
21 "name": "qwen2.5-32b-instruct-ali-bailian",
22 "options": {
23 "model": "qwen2.5-32b-instruct"
24 },
25 "override": {
26 "
27 ": "https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions"
28 },
29 "priority": 1,
30 "provider": "openai-compatible",
31 "weight": 100
32 },
33 {
34 "auth": {
35 "header": {
36 "Authorization": "Bearer {CUSTOM_API_KEY}"
37 }
38 },
39 "checks": {
40 "active": {
41 "concurrency": 10,
42 "healthy": {
43 "http_statuses": [
44 200,
45 302
46 ],
47 "interval": 30,
48 "successes": 1
49 },
50 "host": "{CUSTOM_HOST_1}:{CUSTOM_PORT_1}",
51 "http_method": "POST",
52 "http_path": "/v1/chat/completions",
53 "http_req_body": "{\"model\":\"Qwen/Qwen2.5-32B-Instruct\",\"messages\":[{\"role\":\"user\",\"content\":\"0\"}],\"stream\":false,\"max_tokens\":1}",
54 "https_verify_certificate": false,
55 "req_headers": [
56 "Content-Type: application/json"
57 ],
58 "request_body": "",
59 "timeout": 2,
60 "type": "http",
61 "unhealthy": {
62 "http_failures": 1,
63 "http_statuses": [
64 404,
65 429,
66 500,
67 501,
68 502,
69 503,
70 504,
71 505
72 ],
73 "interval": 30,
74 "tcp_failures": 2,
75 "timeouts": 2
76 }
77 }
78 },
79 "name": "qwen2.5-32b-instruct-b",
80 "options": {
81 "model": "Qwen/Qwen2.5-32B-Instruct"
82 },
83 "override": {
84 "endpoint": "http://{CUSTOM_HOST_1}:{CUSTOM_PORT_1}/v1/chat/completions"
85 },
86 "priority": 5,
87 "provider": "openai-compatible",
88 "weight": 100
89 },
90 {
91 "auth": {
92 "header": {
93 "Authorization": "Bearer {NLB_API_KEY}"
94 }
95 },
96 "checks": {
97 "active": {
98 "concurrency": 10,
99 "healthy": {
100 "http_statuses": [
101 200,
102 302
103 ],
104 "interval": 30,
105 "successes": 1
106 },
107 "host": "{CUSTOM_NLB_HOST}:{CUSTOM_NLB_PORT}",
108 "http_method": "POST",
109 "http_path": "/v1/chat/completions",
110 "http_req_body": "{\"model\":\"Qwen/Qwen2.5-32B-Instruct\",\"messages\":[{\"role\":\"user\",\"content\":\"0\"}],\"stream\":false,\"max_tokens\":1}",
111 "https_verify_certificate": false,
112 "req_headers": [
113 "Content-Type: application/json"
114 ],
115 "request_body": "",
116 "timeout": 3,
117 "type": "http",
118 "unhealthy": {
119 "http_failures": 2,
120 "http_statuses": [
121 404,
122 429,
123 500,
124 501,
125 502,
126 503,
127 504,
128 505
129 ],
130 "interval": 30,
131 "tcp_failures": 2,
132 "timeouts": 3
133 }
134 }
135 },
136 "name": "qwen2.5-32b-instruct-c",
137 "options": {
138 "model": "Qwen/Qwen2.5-32B-Instruct"
139 },
140 "override": {
141 "endpoint": "http://{CUSTOM_NLB_HOST}:{CUSTOM_NLB_PORT}/v1/chat/completions"
142 },
143 "priority": 10,
144 "provider": "openai-compatible",
145 "weight": 100
146 }
147 ],
148 "keepalive": true,
149 "keepalive_pool": 30,
150 "keepalive_timeout": 4000,
151 "ssl_verify": false,
152 "timeout": 600000
153 }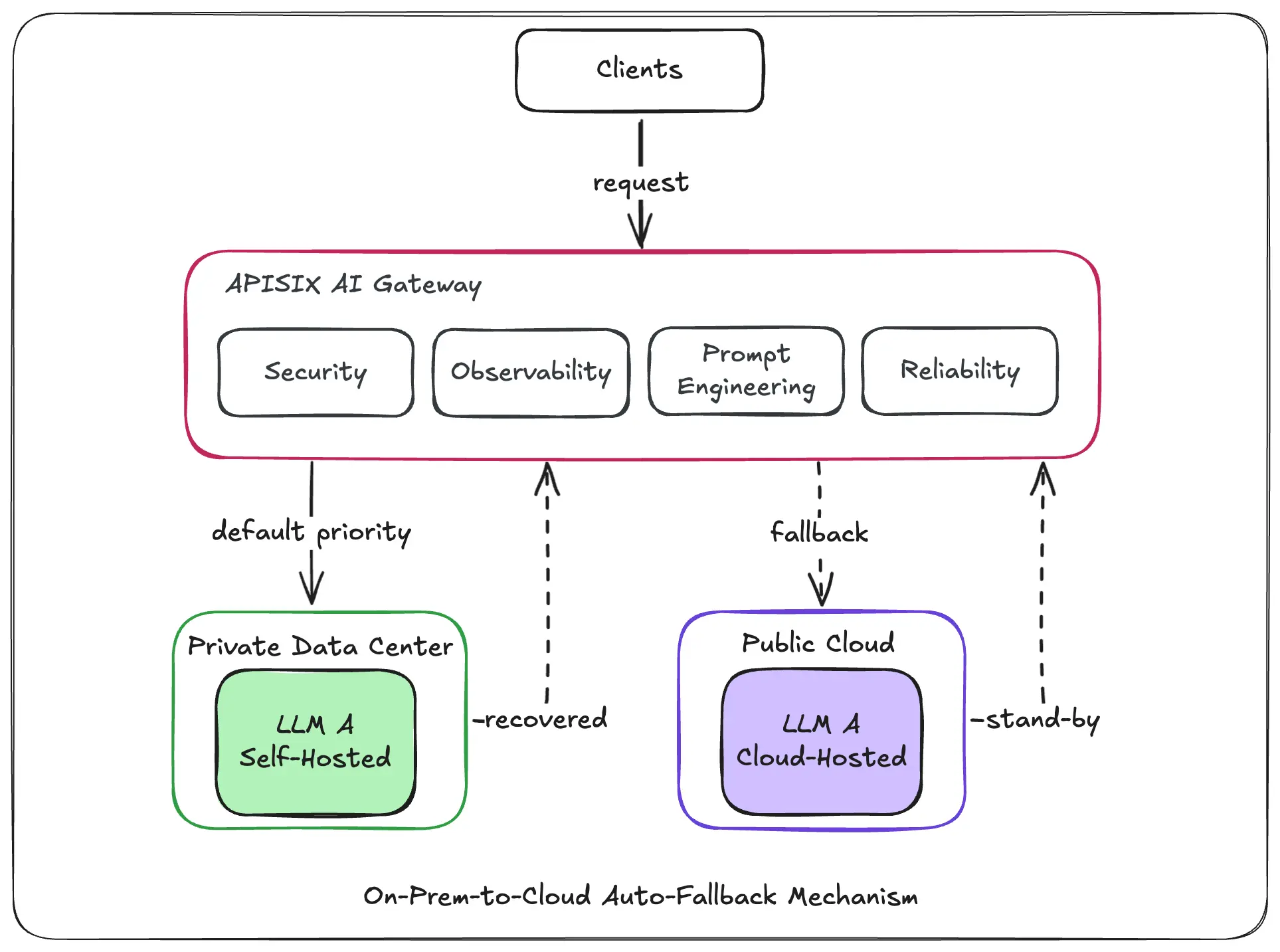
这一机制全程自动化,确保了业务的连续性。运维团队仅通过告警感知状态切换,无需人工介入。该能力不仅显著提升了业务连续性,也极大降低了运维复杂度,成为保障 AI 服务高可用的关键基础设施。
场景 2:基于 token 的限流限速
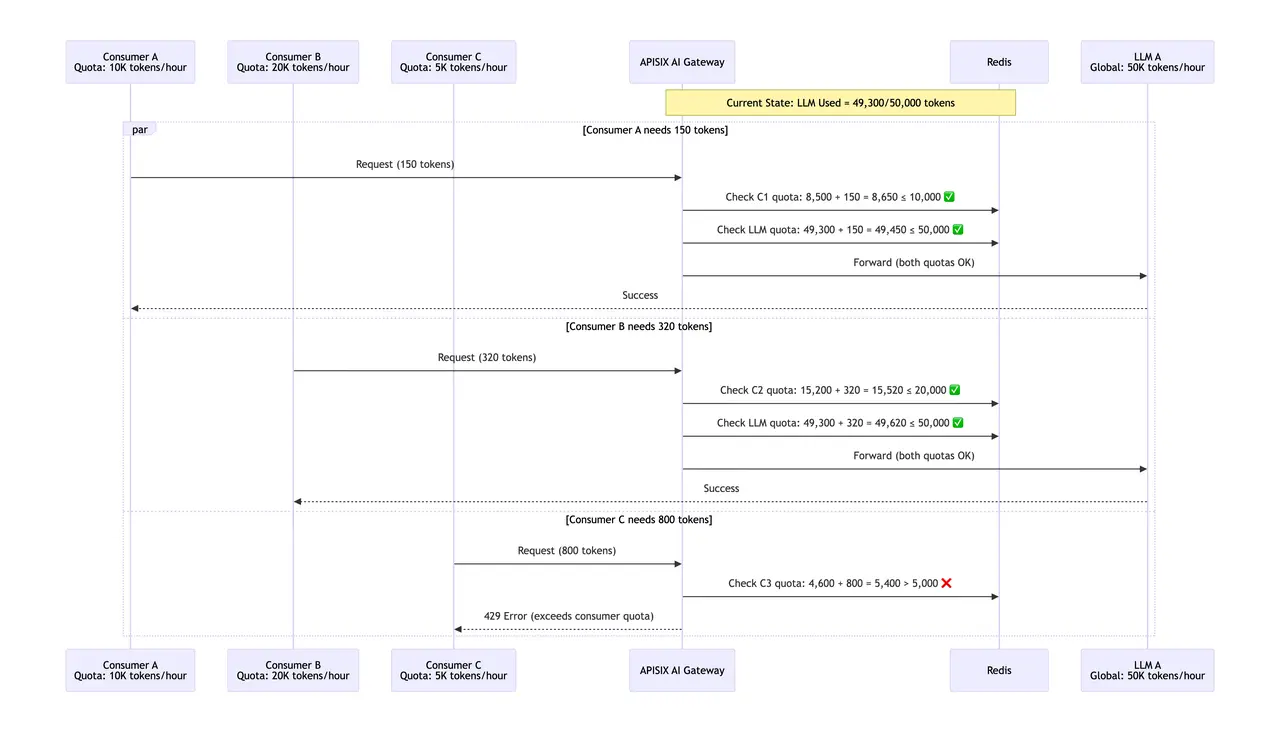
在该企业的 AI 服务多租户架构中,不同用户间的资源分配合理性和隔离性是最核心的诉求。由于不同 AI 模型的 token 成本差异很大,传统的请求次数限流方式无法准确衡量真实资源消耗。因此,必须引入基于 token 量的精细化配额管理与流量控制机制,从而真实反映资源消耗,确保用户间的资源合理调度与成本可控。
在这套机制中,不同的即消费者有各自独立的限流限速配额,同时不同的 LLM 也有独立的 token 限额,二者同时生效,并且消费者的限额优先级高于 LLM 的限额。配额消耗完后,将不允许消费者继续调用 LLM 服务。

例如,在 LLM A 上,消费者 A、B、C 分别有 10,000、20,000、5000 tokens 的配额,而 LLM A 整体有 50,000 tokens 的全局限额。当消费者发送请求时,网关会依次检查两个配额:先验证消费者个体配额是否足够,再确认 LLM 全局配额是否充足。只有两个条件同时满足,请求才会被转发至 LLM A ;任一配额不足都会立即返回 429 错误,并拒绝请求。
在实际配置中,首先启用 ai-proxy-multi 和 ai-rate-limiting 插件,对 LLM 设置限流。
1curl "http://127.0.0.1:9180/apisix/admin/routes" -X PUT \
2 -H "X-API-KEY: ${ADMIN_API_KEY}" \
3 -d '{
4 "id": "ai-proxy-multi-route",
5 "uri": "/anything",
6 "methods": ["POST"],
7 "plugins": {
8 "key-auth": {},
9 "ai-proxy-multi": {
10 "instances": [
11 {
12 "name": "qwen2.5-32b-instruct-ali-bailian",
13 "options": {
14 "model": "qwen2.5-32b-instruct"
15 },
16 "auth": {
17 "header": {
18 "Authorization": "Bearer {NLB_API_KEY}"
19 }
20 },
21 "override": {
22 "endpoint": "https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions"
23 },
24 "priority": 1,
25 "provider": "openai-compatible",
26 "weight": 100
27 },
28 {
29 "name": "qwen2.5-32b-instruct-b",
30 "options": {
31 "model": "Qwen/Qwen2.5-32B-Instruct"
32 },
33 "auth": {
34 "header": {
35 "Authorization": "Bearer {NLB_API_KEY}"
36 }
37 },
38 "override": {
39 "endpoint": "http://{CUSTOM_HOST_1}:{CUSTOM_PORT_1}/v1/chat/completions"
40 },
41 "priority": 5,
42 "provider": "openai-compatible",
43 "weight": 100
44 }
45 ]
46 },
47 "ai-rate-limiting": {
48 "instances": [
49 {
50 "name": "qwen2.5-32b-instruct-ali-bailian",
51 "limit": 50000,
52 "time_window": 3600
53 },
54 {
55 "name": "qwen2.5-32b-instruct-b",
56 "limit": 50000,
57 "time_window": 3600
58 }
59 ],
60 "rejected_code": 429,
61 "limit_strategy": "total_tokens"
62 }
63 }其次,创建 3 个 consumer,并分别为 consumer 配置对应的限流。ai-consumer-rate-limiting 插件用于专门限制 consumer 的限流,以消费者 A 为例,配置如下:
1curl "http://127.0.0.1:9180/apisix/admin/consumers" -X PUT \
2 -H "X-API-KEY: ${ADMIN_API_KEY}" \
3 -d '{
4 "username": "consumer_a",
5 "plugins": {
6 "key-auth": {
7 "key": "consumer_a_key"
8 },
9 "ai-consumer-rate-limiting": {
10 "instances": [
11 {
12 "name": "qwen2.5-32b-instruct-ali-bailian",
13 "limit_strategy": "total_tokens",
14 "limit": 10000,
15 "time_window": 3600
16 },
17 {
18 "name": "qwen2.5-32b-instruct-b",
19 "limit_strategy": "total_tokens",
20 "limit": 10000,
21 "time_window": 3600
22 }
23 ],
24 "rejected_code": 429,
25 "rejected_msg": "Insufficient token, try in one hour"
26 }
27 }
28 }'
这个方案能有效防止单个消费者过度消耗影响其他用户,保护后端 LLM 实例不被突发流量冲垮,基于实际 token 消耗进行配额管理,也为不同级别的用户提供差异化的服务。
APISIX AI 网关带来的价值
技术团队通过构建统一的 AI 网关,收敛统一的 AI 流量入口,显著提升了模型服务的整体使用效率与管理能力。主要成效有以下几个方面:
1. 简化大模型调用,降低使用门槛
AI 网关为所有模型服务提供统一的访问地址与密钥,用户无需关注后端模型部署与运维细节,只需通过固定入口即可灵活调用各类模型资源,极大降低了 AI 能力的使用门槛。
2. 实现资源集中管理,服务稳定
如果缺乏统一的 AI 网关,各业务方需自行搭建并维护模型服务,尤其在面对大模型等高资源消耗场景时,将导致 GPU 等资源的重复投入与浪费。通过统一纳管与调度,实现了资源高效利用,并在网关层面集中保障服务稳定性。
3. 统一管控,流量安全有保障
作为所有 AI 流量的统一收口,AI 网关成为公共能力实施的关键节点。在这个节点上,可以集中实现身份认证、访问审计、内容安全审查、异常请求防护以及输出内容过滤等一系列治理与安全措施,从而系统化提升平台整体可控性与安全性。
AI 网关的演进方向及展望
随着 AI 融入研发、制造、销售的各个环节,该行业标杆企业的目标正在从“接入模型”转向“构建统一 AI 平台”。在这一过程中,AI 网关不再只是流量分发的节点,而是逐步演进为整个 AI 能力系统的调度核心。未来它将承载包括 MCP(Model Context Protocol)、多智能体协作(A2A) 等新能力,演进为企业的 AI 操作系统中枢。
对于该家电企业而言,当前阶段的重点,是打好基础:让每一次请求都可观测、可调度、可治理。
在将 APISIX AI 网关深度应用于业务场景的过程中,双方也在共同探索面向下一代 AI 基础设施的演进方向。随着大模型推理等 AI 原生负载逐渐成为核心业务流量,团队在实践中观察到,AI 流量在调度敏感性、响应模式与服务治理维度上,与传统 Web 流量存在显著差异。这为网关的持续进化提出了新命题:
- 更智能的流量调度:当前负载均衡策略擅长处理高并发、快响应的传统流量。面向 AI 服务,我们希望能引入 GPU 负载、推理队列深度、单请求延迟等指标,实现基于服务实时能力的智能分发,让资源利用更高效,响应更稳定。
- 感知后端服务的状态:当模型服务出现响应变慢、队列堆积时,网关应能更快感知、更快切换。我们正在探索如何基于服务实时状态,如推理性能、队列长度等方面,实现动态路由,保障用户体验平滑流畅。
- 补全可观测性的数据:插件化架构为流量治理提供了灵活性。接下来,技术团队希望进一步加强网关对细粒度指标的采集能力,如上游服务状态码、精准响应延迟等,使其更自然地融入现有监控与日志系统,为故障定位与系统优化提供坚实支撑。
在 AI 流量成为企业关键负载的时代,API7 与全球领先的跨国家电巨头共同探索出一条“网关智能化”的演进路径。它既是一种技术升级,也是一种组织能力的再造——让 AI 真正成为企业的底层操作能力,而不是一个被动的工具。